Content
 I am hosting a series of Data Literacy Workshops for the MTC. Read More ›
I am hosting a series of Data Literacy Workshops for the MTC. Read More ›
Content
 Here is the decision matrix I use when evaluating software purchasing, implementation, and deployment decisions Read More ›
Here is the decision matrix I use when evaluating software purchasing, implementation, and deployment decisions Read More ›
Content
 At the MTC we offer a service for our customers that I call Data Science-as-a-Service. You could also call it Rent-a-Data Scientist. In this article I will show you some ways to leverage this offering. Read More ›
At the MTC we offer a service for our customers that I call Data Science-as-a-Service. You could also call it Rent-a-Data Scientist. In this article I will show you some ways to leverage this offering. Read More ›
Content
 More companies are adopting data lakes and self-service analytics. The problem is data governance has not kept up with the new technologies and the needs of modern analytics. In this article I'll show you some ways to modernize your governance strategies to achieve your business objectives. Read More ›
More companies are adopting data lakes and self-service analytics. The problem is data governance has not kept up with the new technologies and the needs of modern analytics. In this article I'll show you some ways to modernize your governance strategies to achieve your business objectives. Read More ›
Content
 Some data vendors are claiming _the dashboard is dead_. Doubtful. But some of the underlying premises are worthy of discussion. You just might be doing it wrong. Read More ›
Some data vendors are claiming _the dashboard is dead_. Doubtful. But some of the underlying premises are worthy of discussion. You just might be doing it wrong. Read More ›
Content
 Customer Lifetime Value is one of those key metrics every business needs to know. But traditionally that's been difficult to do. Read More ›
Customer Lifetime Value is one of those key metrics every business needs to know. But traditionally that's been difficult to do. Read More ›
Content
 Are you convinced that your outsourced analytics project will succeed? Every day at the Microsoft Technology Center I talk to customers that are underwhelmed with their consultant partners. I wrote an article where I show you THE ONE THING that you should do to guarantee success in your next outsourced analytics project. To my consultancy friends: read on to see what you should be doing to bring your practices into the Prescriptive Analytics Age. Read More ›
Are you convinced that your outsourced analytics project will succeed? Every day at the Microsoft Technology Center I talk to customers that are underwhelmed with their consultant partners. I wrote an article where I show you THE ONE THING that you should do to guarantee success in your next outsourced analytics project. To my consultancy friends: read on to see what you should be doing to bring your practices into the Prescriptive Analytics Age. Read More ›
Content
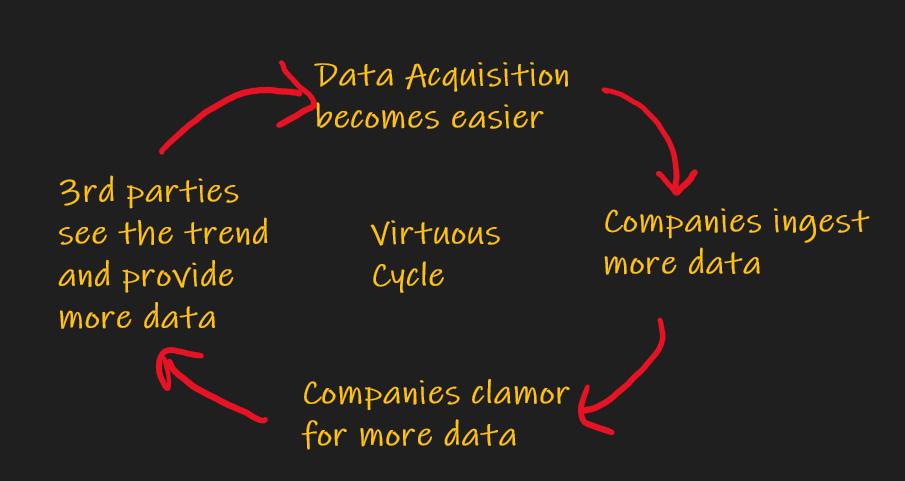
 Here are some actionable ideas to get you thinking about how to leverage altdata Read More ›
Here are some actionable ideas to get you thinking about how to leverage altdata Read More ›
Content
We are living in a data sharing environment. Here is how you can leverage altdata in your data analytics Read More ›
Content
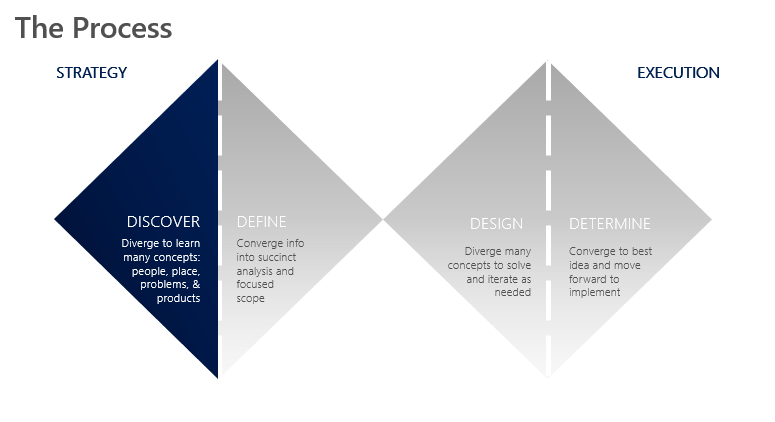
Why Design Thinking is a key tenant of successful analytics projects Read More ›
Content
 For years the IT debate was 'Build vs Buy'. That's the wrong way to look at it in the age of Cloud. It's really 'Build vs Die' Read More ›
For years the IT debate was 'Build vs Buy'. That's the wrong way to look at it in the age of Cloud. It's really 'Build vs Die' Read More ›
Content
 DQ does kinda matter. Why data quality and master data management projects fail and what you can do to remove risk. Read More ›
DQ does kinda matter. Why data quality and master data management projects fail and what you can do to remove risk. Read More ›
Content
 Data scientists and Marketing Departments: you can learn a lot more from TikTok than just how to dance Read More ›
Data scientists and Marketing Departments: you can learn a lot more from TikTok than just how to dance Read More ›
Content
 I was the Season 5 premiere episode guest on the Data Driven Podcast. Being controversial as always. Read More ›
I was the Season 5 premiere episode guest on the Data Driven Podcast. Being controversial as always. Read More ›
Content
 E-commerce isn't really dead, it's just 'table-stakes' now. We should be preparing for The Next Thing: A-Commerce Read More ›
E-commerce isn't really dead, it's just 'table-stakes' now. We should be preparing for The Next Thing: A-Commerce Read More ›
Content
 There are a few books worth re-reading every few years. The Goal is one of them. Read More ›
There are a few books worth re-reading every few years. The Goal is one of them. Read More ›
Content
 I presented 2 successful sessions at the annual Berkadia PolarisCon. Read More ›
I presented 2 successful sessions at the annual Berkadia PolarisCon. Read More ›
Content
 I helped one of my customers win a Forrester 2020 Enterprise Architecture Award. Read More ›
I helped one of my customers win a Forrester 2020 Enterprise Architecture Award. Read More ›
Content
 I am hosting a blockchain ideation & hackathon for the next virtual Azure DataFest scheduled for July 2 Read More ›
I am hosting a blockchain ideation & hackathon for the next virtual Azure DataFest scheduled for July 2 Read More ›
Content
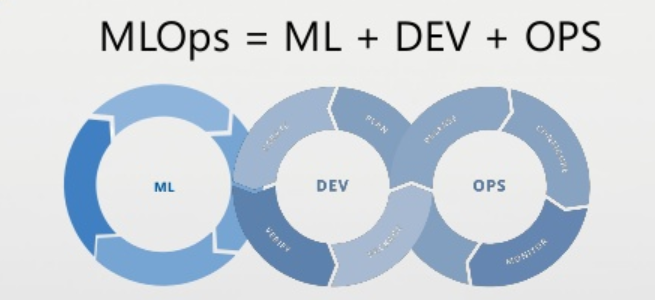 Bring your data scientists, developers, and Ops Guys together for the MTC MLOps Workshop and Hackathon Read More ›
Bring your data scientists, developers, and Ops Guys together for the MTC MLOps Workshop and Hackathon Read More ›
Content

Content
 DBC files are difficult to work with. Here's the fast way to convert them to ipynb files Read More ›
DBC files are difficult to work with. Here's the fast way to convert them to ipynb files Read More ›