
Data Sharing as a Replacement for ETL
This is Part 2 of a series of articles on leveraging alternative datasets to provide lift. Part 1 is an overview of altdata and Part 3 has examples of altdata sets to pique your creativity.
Altdata is any non-traditional dataset from a third party that can semantically enrich your existing data to provide competitive differentiation. When we have conversations with Chief Data Officers at the Microsoft Technology Center (MTC) we find that they desperately want to leverage altdata, but they can’t. The consensus is that data ingestion takes too long and the data will ossify too quickly.
In my previous altdata article I showed some methods to shorten the time-to-analytics. Using vendor-provided APIs is one method, but APIs honestly aren’t a great solution when you are dealing with larger datasets that are being updated in real-time. Best practices and patterns like ELT vs ETL help a bit, but here’s the best solution: Stop doing ETL. Just don’t do it. That includes calling APIs and any kind of data ingestion. Just don’t do it.
Anecdotally, ETL, and any of its forms that copy data around, are one of the top reasons why data projects fail. It takes too long to ingest data to a local compute environment before an analyst can evaluate the data to see if, in fact, it does provide competitive differentiation. If we can quickly determine that a given dataset is not adding value we can fail-fast without writing a single line of ETL code.
 The data community is moving in the direction of “data sharing”. In its simplest form, data sharing is where a 3rd party gives you access to their data lake (or database, or warehouse, etc). The data already has a well-known schema and I simply need to copy it locally where I can begin doing Exploratory Data Analytics (EDA). In more advanced forms of data sharing the 3rd party will allow me to attach their storage directly to my cloud compute thereby skipping the “data copying”. I’m doing EDA in minutes.
The data community is moving in the direction of “data sharing”. In its simplest form, data sharing is where a 3rd party gives you access to their data lake (or database, or warehouse, etc). The data already has a well-known schema and I simply need to copy it locally where I can begin doing Exploratory Data Analytics (EDA). In more advanced forms of data sharing the 3rd party will allow me to attach their storage directly to my cloud compute thereby skipping the “data copying”. I’m doing EDA in minutes.
The cloud enables robust data sharing. For a data professional the primary difference between doing data in your data center vs doing data in the cloud is the fact that in the cloud I can separate storage from compute. For example, in a traditional RDBMS the query engine (the compute) is tightly coupled with, and optimized for, the storage engine. In the cloud I can take any compute engine I want and attach my storage (for example, an Azure storage account) to it. This allows a data scientist to use python as the compute engine, a business analyst can use Power BI, and a data engineer can use Spark…all on the same data in the data lake. This is the heart of data sharing.
Why is ETL such a risky activity for most data projects?
ETL is the process of copying data from one place to another, likely doing some semantic-enrichment in the process. Here are some of the issues with ETL:
- There aren’t enough ETL developers in most shops. These are specialized skills in high demand and the backlogs are long for most shops. If we can avoid ETL, and hence avoid engaging these precious skillsets, we should be able to eliminate some risk. We do this by querying data where it lives.
- Copying data involves multiple data interchange formats and some of them, like csv files, are not well-defined and cause grief and data quality problems. Even JSON, IMO, is a horrible data interchange format…it’s bloated and doesn’t handle dates well, but it’s the backbone of almost all REST-based APIs.
- We need to have a destination for the data copy. This becomes contentious in many shops. A typical question: “Where in the data warehouse are we going to stick this new altdata?” Fact is, we haven’t yet done the analysis to see if this data is valuable, we need to put it in temporary storage until we can enrich it and determine its value. We do this using data lakes where we can join multiple datasets together to find the nuggets of gold. If you don’t have a data lake (or don’t have access to a data sandbox) this becomes difficult. Instead, we can query the data where it lives.
- ETL coding takes time. With altdata the goal is to do analytics really quickly. In many cases we want to leverage external datasets as the business transaction is occurring to add value. We can’t do that if the ETL process runs as a n overnight batch job.
- In most organizations, adding data to a data warehouse (via ETL) requires a security review and data governance activities. But again, we haven’t determined if the new data is valuable. It would be better to profile the data where it lives and defer these decisions.
Internal and External Data Sharing
There are 2 types of data sharing: internal and external.
External is the simplest: I connect to a dataset outside of my organization. I might need to purchase a subscription to this data or it might be an open dataset (like Azure’s Open Datasets).
Internal data sharing is where different lines-of-business provide access to their data marts or data lakes. Yes, we tend to see many of our customers with multiple data lakes. That’s OK in the Age of Data Sharing. If these data sources become data silos then we can’t get the most economic value out of our data.
The Biggest Obstacle to Data Sharing: Culture
The biggest obstacle to data sharing, anecdotally, is culture. When we talk to companies at the MTC we often hear that they aren’t yet ready to ingest external data sources, usually due to the reasons listed above. When we dig a little deeper we find a more pervasive problem. We often hear about information hoarding where some business units are afraid to provide other departments with access to data because it may result in the loss of their influence and power.
Wow!
 These companies tend to have many department-level data lakes/marts/warehouses with duplicated data, data with different levels of aggregation, governance, and quality, and no standard data interchange formats. In economics, scarcity leads to demand. But data doesn’t have to be scarce. It’s pretty easy to copy it around. But data is rivalrous, that is, whoever owns the data controls the power. The result: data silos and information hoarding.
These companies tend to have many department-level data lakes/marts/warehouses with duplicated data, data with different levels of aggregation, governance, and quality, and no standard data interchange formats. In economics, scarcity leads to demand. But data doesn’t have to be scarce. It’s pretty easy to copy it around. But data is rivalrous, that is, whoever owns the data controls the power. The result: data silos and information hoarding.
This mindset is difficult to overcome, but it can be done. Start with a few use cases where we can quickly prove that data sharing is akin to a rising tide that lifts all boats. One way is to share data talent among teams. We see that some teams have great data scientists and analysts but lack ETL developers, while others have the reverse. By sharing resources we gain cross-training and intra-departmental trust.
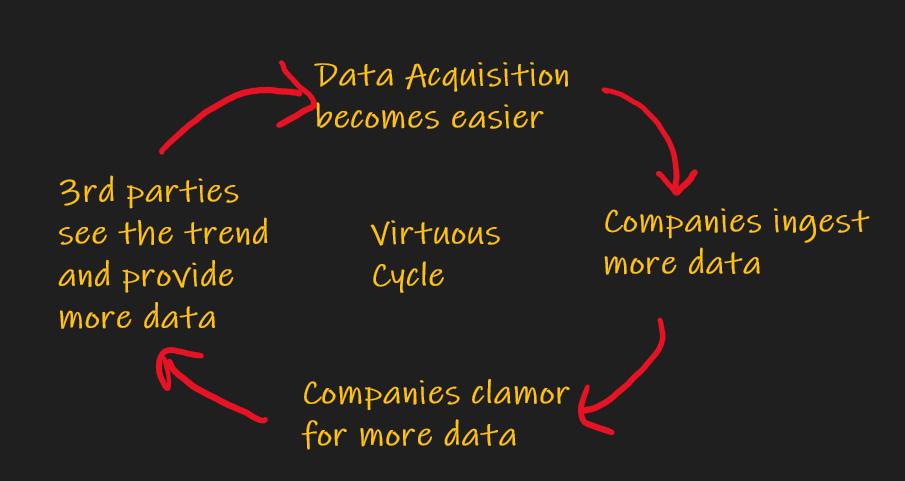
Here’s an example: let’s say low-level customer sales attributes sit in a data mart owned by the sales department. Clearly finance and marketing will have access to aggregated sales data, but if the sales department owns the data silo with the raw, valuable data, other teams can’t benefit. With a zero dollar marginal cost those low level sales metrics can be used by marketing to improve cac (customer acquisition cost) and reduce customer churn. The R&D team can use that same data to determine which new features to prioritize. This creates a virtuous cycle: as more departments see the value of data sharing, more data will be shared. Using data sharing paradigms (connecting remote datastores to your compute) the marginal cost of data reuse is nearly zero and you can quickly measure the value-add.
We are living in a “sharing economy”. Some business leaders think that protecting their data is a source of power. It probably is. But more power can be gained by sharing it. How Can we do this?
Here are some methods I’ve seen that will allow you to implement data sharing quickly.
The Data Marketplace: Data should be a shopping experience
This is the model I like best. A data marketplace is a lot like an e-commerce site. I can shop around to find the data I need. This enables self-service analytics. In some cases the 3rd party will allow “data virtualization” where you can attach directly to the data and query it without bringing it into your data lake (in-place access). If the data is deemed valuable after it is analyzed then we can determine if we want to copy the data into our local data stores.
The problem is: there are no really good, comprehensive data marketplaces for 3rd party data right now. The major cloud vendors have cataloged public datasets already. For paid and subscription altdata, you still have to know where to go to find what you need. It won’t be long before we have cloud-based data marketplaces that will facilitate data interchange.
 Internally, you can create your own data marketplace to combat information hoarding. The simplest way to do this is with a good data catalog. If you are a Microsoft shop our Azure Purview is a great option. It will allow you to tag data sources, search them, create sample data, create documentation, show lineage, and list contact information.
Internally, you can create your own data marketplace to combat information hoarding. The simplest way to do this is with a good data catalog. If you are a Microsoft shop our Azure Purview is a great option. It will allow you to tag data sources, search them, create sample data, create documentation, show lineage, and list contact information.
The Data Lake Sharing Model
Essentially you distribute keys or tokens to users that would like to access your data (lake). Those users can then connect to your data by mounting it to their compute engine. By far this is the most common model I’ve seen for external data sharing. This is a common pattern in industries where data is commonly shared between business partners.
The only downside to this model is most cloud providers will charge data egress fees to the owner of the storage. This means that the data producer will be charged based on how much data is extracted by the consumer. This could be expensive but can be creatively handled with things like chargeback models and throttling.
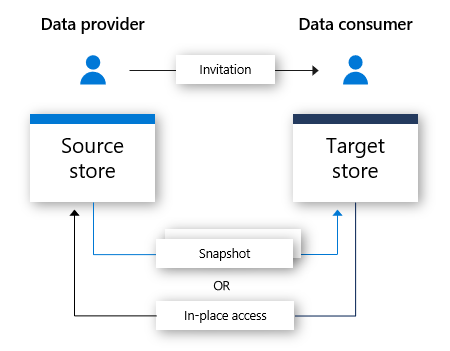 Azure Data Share is another Microsoft offering that provides an additional wrapper around your data and will allow you to share additional data assets like data warehouse data and SQL Server data without having to understand the minutiae of SAS tokens.
Azure Data Share is another Microsoft offering that provides an additional wrapper around your data and will allow you to share additional data assets like data warehouse data and SQL Server data without having to understand the minutiae of SAS tokens.
The Data-as-a-Service Model
The DaaS model is very close to the Data Marketplace and Data Lake Sharing Models. The DaaS offering goes a step further to getting us to true “Self-Service Analytics”. The data storage implementation is totally abstracted away from the analyst. The analyst is given a query interface directly over all of data sources and is simply writing queries. Data access hassles are abstracted away.
The Enterprise Service Bus Model
In this model the data producer allows you to subscribe to their “events”. It is your responsibility to ingest those events (probably in a data lake) and perform any analytics. This is definitely not as easy to do as standard data sharing, but this method has been around for years. An example: you would like to ingest real-time telemetry about your fleet vehicles from Ford and GM. After you request this data you will be allowed to subscribe to the real-time data hub where you can choose how often you want to pull updates. This is a common enterprise integration pattern but there is no single standard so you can expect to have your IT staff spend some time just ingesting the data to get it ready for your analysts. But, you will have access to real-time data.
An Example of Data Sharing: Weather data
NOAA provides hourly worldwide weather history data for free via Microsoft Azure Synapse Dataset Gallery. The Integrated Surface Dataset (ISD) is composed of worldwide surface weather observations from over 35,000 worldwide stations. Parameters included are: air quality, atmospheric pressure, atmospheric temperature/dew point, atmospheric winds, clouds, precipitation, ocean waves, tides and more. ISD refers to the data contained within the digital database as well as the format in which the hourly, synoptic (3-hourly), and daily weather observations are stored.
Let’s say you quickly want to see if weather data can provide supply chain efficiencies.
The first thing I need to do is EDA. I need to familiarize myself with what is available in the dataset. I don’t want to copy the data locally and I want to see the most up-to-date data. In about 5 minutes I wrote this query:
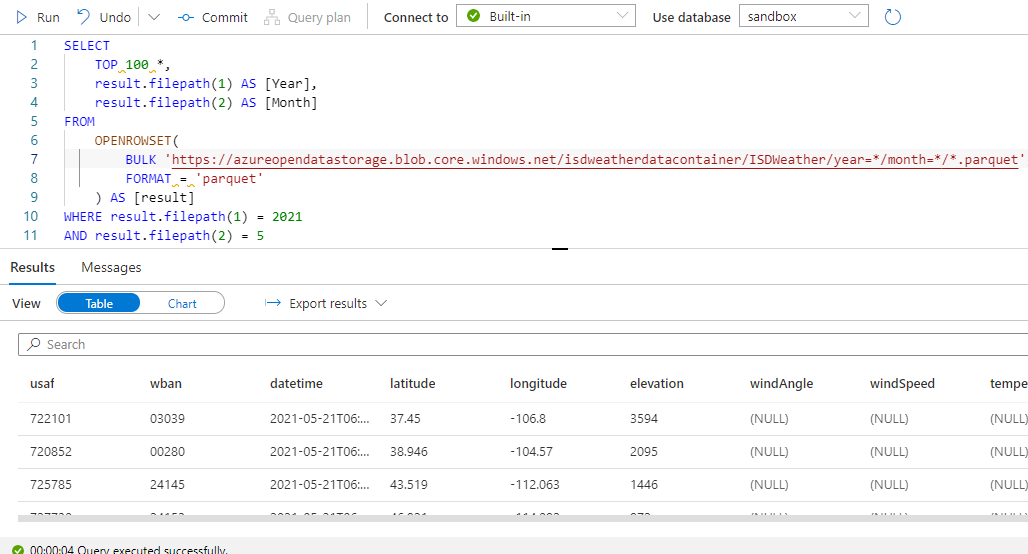
This gets into the weeds, but notice I am querying the ISDWeather dataset directly and never copied it locally. I added a WHERE filter to show just the most recent data. I can quickly see that I must do some research to determine what usaf and wban are used for. I also note that I’m missing temperature in my sample data. I may need to determine if that will be a problem. I do have the lat/long coordinates so I should be able to use that, as well as the datetime, to marry this data with my supply chain data.
And notice this query returned data in 4 seconds! That’s excellent time-to-analytics!!! This is so much better than doing ETL.
I need to understand this dataset better. But I was able to do all of this in just a few minutes.
This is the promise of data sharing: Faster time-to-value.
The MTC can help
The Microsoft Technology Center is a service that helps Microsoft customers on their Digital Transformation journey. We know that  successful data projects are less about the technology and more about the process and people. Data sharing is a great way to avoid ETL and put data in the hands of your analysts quickly. At the MTC, we’ve been doing data for years. We are thought leaders, conference speakers, and former consultants and executives. We’ve learned the patterns that will help you execute successful data sharing projects. And with the cloud we can execute in hours-to-days instead of months.
successful data projects are less about the technology and more about the process and people. Data sharing is a great way to avoid ETL and put data in the hands of your analysts quickly. At the MTC, we’ve been doing data for years. We are thought leaders, conference speakers, and former consultants and executives. We’ve learned the patterns that will help you execute successful data sharing projects. And with the cloud we can execute in hours-to-days instead of months.
Does this sound compelling? SUCCESS for the MTC is solving challenging problems for respected companies and their talented staff. Does that sound like folks you can trust on your next project? The Digital Transformation is here, and we know how to help. Would you like to engage?
In my next article I’ll give you some creative ideas for altdata that you can leverage today to provide competitive advantage.
Are you convinced your data or cloud project will be a success?
Most companies aren’t. I have lots of experience with these projects. I speak at conferences, host hackathon events, and am a prolific open source contributor. I love helping companies with Data problems. If that sounds like someone you can trust, contact me.
Thanks for reading. If you found this interesting please subscribe to my blog.
Related Posts
- Data Literacy Workshops
- Software Implementation Decision Calculus
- MTC Data Science-as-a-Service
- Top 10 Data Governance Anti-Patterns for Analytics
- The Dashboard is Dead, Probably?
Dave Wentzel CONTENT
data science Digital Transformation