
Presentations
I have developed and delivered these presentations for local User Groups, private consulting engagements, OpenHacks, and one-to-many customer workshops. Where I have links, you may copy, change, or reference this material as you like. A simple attribution is always appreciated. For sessions without links I simply haven’t had the time to get the materials organized properly with customer-identifiable information removed, etc. Feel free to contact me if you want additional details.
Links to My Speaker Profiles
Data Literacy Series
This is a workshop series I do that focuses on data literacy:
Data Literacy is a fundamental skill for the Digital Age. While companies have lots of data, very few folks know how to leverage data to be an insights-driven company. At the MTC, we want to change that. We created a workshop series for December to help evangelize data fluency.
“We have a data lake, a data warehouse, and Power BI…but no one has still been able to show us how to leverage our data assets to provide actionable intelligence.” – heard during a recent MTC engagement
Thinking Like a Data Scientist
December 10 1-4pm EST
Does data science terminology seem overly confusing? Would you like to learn more about data science but are scared of the math? You don’t need to hire “data scientists” to think like a data scientist. Fact is, you’re probably doing “data science” today. You don’t need to know a lot of python to be an effective data scientist. We’ll cover important terminology and use cases and then dive-in by exploring data with tools you are already using. Even if you employ data scientists today this session will help you understand how to work better with data.
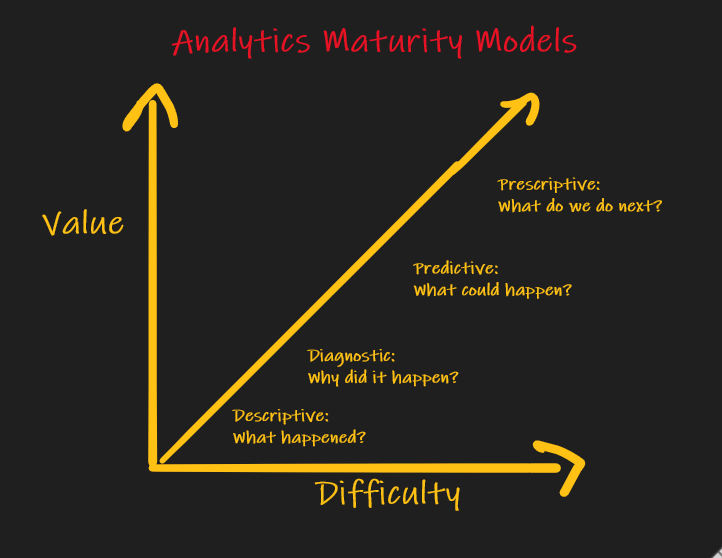
Prescriptive Analytics: The Future of Data in the Enterprise.
December 15 1-3pm EST
Most companies are doing reporting and dashboarding (Descriptive Analytics) today and some are doing Predictive Analytics (ML, AI, data science). The future is Prescriptive Analytics…using data to solve complex business problems. Business leaders want to know…“what do I do next?”. This requires thinking differently about how you utilize data. We’ll discuss the tech, but more importantly, how to think about data differently and structure a successful Prescriptive Analytics team that can use data to support a decision architecture.
How to NOT make analytical cognitive mistakes
December 6 1-3pm EST
Companies want to be “data-driven” and use data to generate actionable insights. Unfortunately that sometimes mean we accidently use data to support our biases and preconceptions. Data is hard. Numbers are hard. Make sure you don’t mistakes interpreting your data. We’ll show you some methods that data scientists use to avoid making analytical mistakes.
Design Thinking as a way to avoid data project failures.
December 17 1-3pm EST
Analytics projects are risky and have a high rate-of-failure. Why is that? Is there a better way to do these projects? The best data scientists practice “human-centric, empathetic design thinking”. This allows us to get to the real business requirements and enables us to openly discuss solutions. Then we use Rapid Prototyping to show how to take a design and implement it.
But we won’t just “teach” you Design Thinking…we’ll actually use it with a real-world use case so you can see it in action.
Building a Data CoE: Analytics Best Practices
December 16 1-3pm EST
Most companies already have a data Center of Excellence. But is it optimized for self-service analytics? Is focusing on Data Governance and Data Quality stifling innovation? Is your CoE promoting data literacy and fluency? Why do data centralization efforts fail and is there a better way? We’ll answer all of these questions as well as give you a concrete set of implementable Best Practices that you can incorporate into your CoE.
Presentations
| Session Title | Abstract | Target Audience | Duration | Additional Information |
|---|---|---|---|---|
| Databricks 101 | This is a brief introduction to Databricks. We build a data engineering and ML workflow using blob storage. | Data Professionals | 2 hours | Git Repo |
| Data Engineering With Databricks-Hackathon | This is a 1-3 day hackathon where we teach end-to-end data engineering with Databricks. We also weave in ADF, Python code containerization, and DevOps. This is a 400+ level session. You will walk away understanding Best Practices by actually writing code to implement a number of common data engineering tasks. | Data Professionals, DevOps Engineers | 1-3 days | Contact me for details |
| Performance Tuning SQL Data Warehouse | Get a better understanding of how an MPP works by understanding how to tune for performance. | Data Professionals | 2 hours | Git Repo |
| AI for Intelligent Cloud and Edge: Discover, Deploy, and Manage with Azure ML Services | Includes reproducible demos. Delivered at Philly Tech Week 2019. | Business and Tech Leaders | 1 hour | Git Repo |
| So You Want to Be a Data Scientist? | Does R seem like an alien language to you? Does data science terminology seem overly confusing? Would you like to learn more about data science but are scared of the math? Fact is, you’re probably doing “data science” today. You don’t need to know a lot of R or python to be an effective data scientist. We’ll cover important terminology and use cases and then dive-in by exploring data with tools you are already using. We’ll deploy a modern data science workstation in just 10 minutes. Finally, we’ll put it all together and create a predictive web service using Azure Machine Learning. | Developers and Analysts | 2-4 hours | |
| Data Science for the Rest of Us | I show you just enough "theory" so you can begin your Data Science Journey. We cover tooling that anyone can learn quickly. We cover a few great uses in different industries that you can begin using today. | Data Analysts and Developers | 1-2 hours | Presentation |
| EndtoEndBigData | Getting started with Big Data can be daunting if you haven't utilized the tooling. In this session we'll start with a large data set and load it into Spark/Databricks using standard Big Data ingestion techniques. We'll build a basic ML model using Jupyter notebooks against Spark to show you data analytics. We'll finish with Power BI visuals against the data. The goal is to show the end-to-end Data Science Process to discover and enrich and model data. | Data Engineers | 6 hours | Git Repo |
| Containerization for Data Professionals | This is a hackathon/workshop to learn Docker and Kubernetes by deploying and using SQL Server containers. We start by running things locally on our workstations, then scale the solution to Azure. | Data Professionals | 6 hours | Git Repo |
| WORKSHOP: Deep Learning, AI, and ML: A Hands-on Hack | Have you read about Deep Learning but don't understand it? Did you ever wonder how computer vision AI really works under-the-covers? Wondering how AI can transform your business? In this "hackfest" we will look at a real computer vision use case for a REAL company. Then we'll break apart the solution and show you how to develop it, even if you are NOT a developer. Scattered throughout the day we'll learn the theory behind the implementation and show you how to develop DevOps pipelines to deploy the solution. Whether you are a seasoned data scientist, a developer wanting to learn new skills, or a business person that has never touched a Jupyter notebook but wants to see the Art of the Possible, this session is for you! | Data Architects, Data Scientists, CTO | 6 hours | Git Repo |
| Azure End-to-End Big Data | In this workshop you will learn the main concepts related to advanced analytics and Big Data processing and how Azure Data Services can be used to implement a modern data warehouse architecture. You will understand what Azure services you can leverage to establish a solid data platform to quickly ingest, process and visualise data from a large variety of data sources. The reference architecture you will build as part of this exercise has been proven to give you the flexibility and scalability to grow and handle large volumes of data and keep an optimal level of performance. | Data Professionals | 6 hours | Git Repo |
| Notebooks Everywhere: Using Jupyter and Notebooks for your day-to-day tasks | Learn how to think like a data scientist by learning all about Jupyter Notebooks | DevOps | 1-2 hours | Git Repo |
| MLOps End to End Workshop | We use Databricks, Azure Machine Learning Services, Azure DevOps, and Jupyter Notebooks to build 3 data pipelines. There's something for everyone in this hands-on workshop. | DevOps Engineers, Developers, Data Engineers, Data Scientists | 2-4 hours | Git Repo |
| Migrate Your Apps to Azure | This is a full day hands-on workshop where we migrate an entire application to Azure. We first migrate the data to Azure SQL and CosmosDB. Then we migrate the application code to a WebApp using containers. Finally we build DevOps pipelines to deploy future changes using CI/CD pipelines. | Data Professionals and Developers | 2-4 hours | Git Repo |
| Self-Service Analytics: Best Practices | This is from my livestream presentation at Azure DataFest. | Data Scientists, Data Engineers | 1-2 hours | Link to presentation materials |
| Self-Service BI | Self-Service analytics is possible when you give your staff the tools they need to do data discovery and data sandboxing. I accomplish this using Data Lakes (not necessarily using an expensive Hadoop implementation) and Kappa Architecture. Kappa allows ETL/ELT to be accomplished without expensive ETL developers. ETL can be done by your staff as part of data sandboxing. I'll put all of this together for you in this webinar and give you some case studies of implementations I've done with my clients. | Data Analysts, Developments, Program Managers | 1 hour | Watch Webinar |
Older Content
These are older presentations/workshops. I doubt anyone will care about these, except maybe for nostalgia.
| Session Title | Abstract | Target Audience | Duration | Additional Information |
|---|---|---|---|---|
| Practical DevOps Using Azure DevTest Labs | Azure DevTest Labs is a great way to solve common development environment challenges. Self-service deployment can be done quickly AND cost-effectively. By using templates, artifacts, and “formulas” you can deploy the latest version of your application, whether Windows or Linux. This is great for development, testing, training, demos, and even lightweight DR environments. We’ll show you how to get started with DevTest Labs regardless of whether you use Visual Studio. | DevOps | 2-4 hours | |
| Big Data and Hadoop | Don’t know where to start with your Hadoop journey? Is your company considering Hadoop and you want to get up to speed quickly? Just want to modernize your skills? If you answered YES to any of these then this session is for you. Hadoop is a hot skill in the data space but it’s challenging to learn both the new technologies (like Spark and Hive) as well as the modern concepts (like Lambda/Kappa and “streams”). We’ll break down the most important concepts that you need to know and can start using in your job TODAY, even if you don’t have a Hadoop cluster. We’ll do an overview of the important tooling and show you how to spin up a sandbox in minutes. | IT Pros with a Desire to Learn Something New | 2-4 hours | |
| So You Want to Be a Data Scientist? | Does R seem like an alien language to you? Does data science terminology seem overly confusing? Would you like to learn more about data science but are scared of the math? Fact is, you’re probably doing “data science” today. You don’t need to know a lot of R or python to be an effective data scientist. We’ll cover important terminology and use cases and then dive-in by exploring data with tools you are already using. We’ll deploy a modern data science workstation in just 10 minutes. Finally, we’ll put it all together and create a predictive web service using Azure Machine Learning. | Developers and Analysts | 2-4 hours | |
| Implicit Transactions | Have you ever seen sp_reset_connection in Profiler and wondered what it does? Did you ever see an "orphaned spid" with an open transaction and wondered where it came from? Do you run jdbc or dblib data access technologies? If you answered yes to any of these then it is important to understand how implicit transactions work. You may be surprised that transaction handling doesn't always work the way you think it does. | Intermediate to advanced DBAs and Developers | 15-60 mins | |
| Teach Yourself Service Broker in 15 Minutes | You know that asynchronous data eventing is the future. You've heard about Service Broke but it seems too complex and you are not even sure when you should use it. No one needs to understand esoteric queues, services, activators and conversations to get a basic Service Broker solution up and running quickly and reliably. By the end of this session we'll have a service set up to do asynchronous triggers and another service that will "tickle" you every minute and we'll be able to install and tear them down with a single command. | DBAs and Developers | 15-60 mins | |
| Another Way to do DDL | DDL commands can be cumbersome to write. In this session I'll show you a method to do a "properties-based" DDL deployment. By the end of the session we'll have a stored procedure that reliably handles DDL without the need for understanding esoteric DDL syntax. Certainly you can use "scripting wizards" and "SQL compare" tools to do this but I'll show you some benefits that having a custom DDL deployer can handle that the other tools can't. | DBAs and Developers | 1 -2 hours | CodePlex code and presentation |
| NOLOCK | Most of us know that the use of NOLOCK and READ UNCOMMITTED is discouraged. But did you know that NOLOCK does not mean 'no locks' are taken? Did you know that a simple SELECT...WITH (NOLOCK) can cause blocking? Did you know that queries using NOLOCK can actually fail and must be retried just like a deadlock? Did you know that the use of NOLOCK can even cause (spurious) data consistency errors in your logs? We'll look at some examples and I'll show you a good pattern to always use if you absolutely MUST use NOLOCK. | Developers | 15-30 mins | |
| Zero Downtime Database Upgrades | Did you ever need to migrate billions of rows of data from one table structure to another with zero downtime? Did you ever need to refactor multiple huge tables without impacting your online users? Wouldn't it be nice to "stage" the "next" version of your application alongside your existing production objects and just "transfer" them in with almost no downtime? In this presentation I'll show you a little known feature of SQL Server that can do all of this for you...ALTER SCHEMA TRANSFER. | Advanced DBAs and Developers | 1-2 hours | |
| Slay Your UDF Halloween Hobgoblins with SCHEMABINDING | You probably know that scalar UDFs can be evil because of their RBAR (row by agonizing row) nature. But do you know why? They are meant to solve the "Halloween Problem". But you probably don't care about that. If you use SCHEMABINDING on your UDFs you can see dramatic performance improvements and you don't need to worry about Halloween Hobgoblins either. | Developers | 15-30 mins | |
| Get the Actual SQL From a Prepared Execution Call | Did you ever try to run Profiler to help a programmer debug a stored procedure only to find that the stored procedure is never called. Instead you see a bunch of "sp_execute 15" commands. I'll show you some quick methods that you can use to decode "sp_execute 15" to "EXEC YourProcedure". | Intermediate to Advanced DBAs and Developers | 30 mins | |
| Batch Processing and Error Handling | Do you have stored procedures that batch load millions of rows at a time? When one row throws an error the entire batch will rollback. In this session I'll show you what I think is the most-optimal batch size as well as a pattern that can be used to process batches that will efficiently find error rows without aborting entire batches. | Intermediate to Advanced Developers | 15 mins | |
| SQL Server Connectivity Stack Diagnose | Connecting to your SQL Server can become daunting if your environment is customized. How do you troubleshoot if your server listens on an alternative port? How can you determine if a firewall is causing your connection to fail? How do you troubleshoot if your client doesn't have SQL Tools installed? What if you client is Apache/Linux? Why does my handshake with SSPI fail and why am I shaking its hand anyway? Whenever you have connectivity issues the key is to follow the "stack diagnosis" process. In this session we will cover the SQL Server communication stack and how to troubleshoot it using basic network diagnostic tools found on any OS. | DBAs | 30-60 mins | Troubleshooting Connectivity |
| Hadoop for the RDBMS Expert | Struggling to learn Hadoop? Is you company considering a Hadoop deployment and you want to get up to speed quickly? Just want to update your IT skills? If you answered YES to any of these then this session is for you. Hadoop is the hot new skill in the data space and it’s easy to understand the basics and apply what you already know about SQL Server to get up to speed quickly. We’ll cover the latest trends in Big Data and the newest technologies in the Hadoop stack. We’ll show you some great use cases for Hadoop, how to spin up a test cluster in a few mins for free, and how to integrate SQL Server quickly. We’ll also cover cases when Hadoop is NOT the right solution for a given problem. | Devs, DBAs, BI/Reporting Experts | 120 mins | |
| U-SQL in Azure Data Lake | Microsoft created a new language called U-SQL to make big data processing easier on Azure Data Lake. U-SQL provides the power of SQL and the extensibility of C# to make processing of any data - structured or unstructured - easier. U-SQL can be run over your Data Lake without a dedicated HDInsight cluster. It can even query blob storage and Azure SQL database. We'll show you why this offering is so compelling, the development tooling, language capabilities, and use cases. We'll also spend time networking and discussing general Hadoop questions relevant to data professionals who want to learn more about Big Data. | Devs, Data Architects | 120 mins |