
They Should Call Them Evil Spools
In my last post, [[SCHEMABINDING Performance Considerations]], I mentioned problems with Eager Spools. I've written about these many times. They really should be called Evil Spools. To be clear, they do serve an important purpose, but they can often be eliminated without detrimental data quality side effects.
This is just a really quick follow up to that last post ([[SCHEMABINDING Performance Considerations|here]]) that covers some other Eager Spool conditions and methods to remove them from query plans. Most of this I've written about before.
What is an Eager Spool?
- gets a "read-consistent" view of the data. Solves infinite loop and "Halloween Protection" problems with UPDATE statements.
- HP/Eager Spools are also required for:
- INSERT statements where the target table is also referenced in the SELECT statement.
- DELETE statements with self-join relationships.
- certain CTEs (which is one reason why CTE performance is usually worse than many other alternatives). I avoid CTEs whenever possible due to this (the exception is recursive CTEs, which really are very elegant)
- recursive CTEs (very unfortunate, but HP is needed in this situation to get the read-consistent view of the data).
- many "Hole-filling queries"...I got this term from an excellent blog series Paul White did on the Halloween Problem. He does a fabulous job on all of this. More on "hole-filling queries" in a moment...
- a "blocking" operator where that "branch" of the query serializes behind the Spool. The Eager Spool MUST be satisfied before continuing. An operator is non-blocking if it can take a single row and pass it to the next operator (ex Nested Loops). An operator is blocking if the next pipeline step cannot occur until the entire operator is satisfied (ex Hash Match...probing cannot occur before the entire hash is built)
- uses tempdb
- (usually) uses rebinds which are worse than rewinds
- since it is a "blocking operator" it will take more locks and longer-duration locks.
Hole-Filling Queries
A hole-filling query is where you need to INSERT into a table where the key does not already exist. The implementation is usually something like this:
INSERT INTO #TempTable...WHERE NOT EXISTS (select ObjId FROM #TempTable)
- the WHEN NOT MATCHED BY TARGET clause *must exactly* match the USING/ON clause.
- And target must have *a* unique key (anything will do).
Here is an example of a query plan that performed a hole-filling query:

That's a very expensive Eager Spool.
I rewrote the query using a LEFT JOIN and look at the difference:
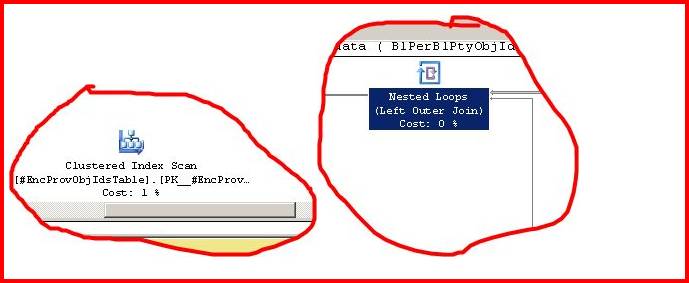
The wall-clock time improvement was just as staggering.
Dave Wentzel CONTENT
sql server performance data architecture