
Vertica Physical Architecture
This post is the next in my Vertica series and covers how Vertica is physically architected. I covered pieces of this when we installed our first Vertica instance. Now we'll go into a bit more detail. This is all leading up to installing a second Vertica node and sharding our data in a manner that helps us with both recoverability and performance.
Instances, Nodes, Clusters, Databases
Only one instance of Vertica can run on a given host. This is also called a node. If a node fails the database will still recover if the cluster has at least 3 nodes. Kinda like RAID 5 for your nodes. HP recommends 4 nodes minimum and more is always better because additional nodes work just like SQL Server's readable secondaries...they are active for querying and updates. They are not just passive cluster nodes. And, they are not necessarily COMPLETE copies of any other node in the cluster, unlike SQL Server. This means, similarly to the concept of RAID 5 for storage, that you can lose a 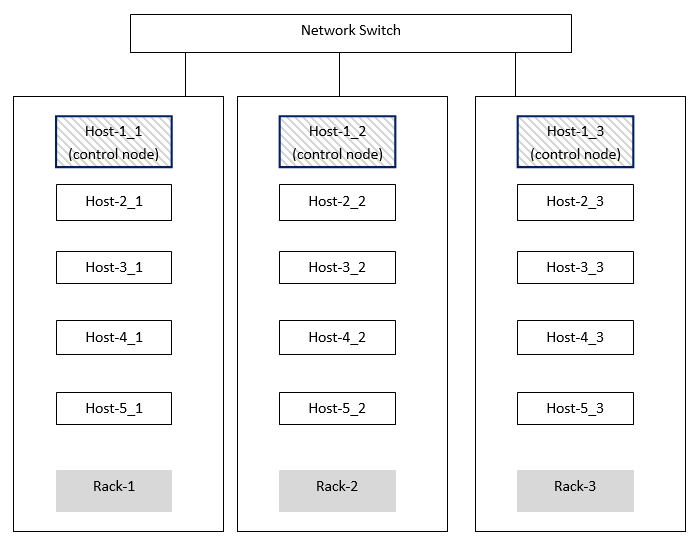 certain number of nodes without bringing your database down. Also, additional nodes with partial (or complete) copies of data also gives you a performance boost when querying.
certain number of nodes without bringing your database down. Also, additional nodes with partial (or complete) copies of data also gives you a performance boost when querying.
There is also something called a "control node" in Vertica. You always have at least one control node but you can have many if your cluster is huge or geographically dispersed. The control node can also migrate to other nodes automatically if the control node goes down without any DBA intervention. The control node is the traffic cop. As queries are submitted to Vertica the control node sends the requests to other nodes (...similar to Map...) to collect data and return it to the control node which then does any final calculations before returning the data to the requestor (...similar to Reduce in MapReduce). All nodes run a process called "spread" which assigns nodes to be the control node if you haven't configured it yourself.
K-safety
"K-safety" is how Vertica measures fault tolerance and is the key to understanding the node-to-data relationship. Let K equal the number of replicas of the data in a given cluster. This is not the same as the number of nodes. The more K-safety you have the more nodes can fail without impacting performance or having the db go offline. When a node comes back online it will automatically recover just like a failed disk in a RAID 5 array. The failed node queries neighboring nodes for missing data. The recovery status can be queried using the Management Console which we'll install and look at in a future post.
The "K" can be 0, 1, or 2 and depends on your physical design. You don't want to screw up your design and end up with something that isn't as k-safe 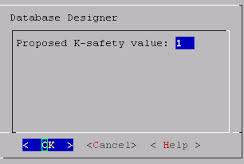 as you planned, not to mention not as performant. The Database Designer (again, we'll cover this in a future post) helps you by noting your design's K-safety level. It offers suggestions on how to improve your k-safety and can even help you convert your existing design to be either more or less k-safe depending on your needs.
as you planned, not to mention not as performant. The Database Designer (again, we'll cover this in a future post) helps you by noting your design's K-safety level. It offers suggestions on how to improve your k-safety and can even help you convert your existing design to be either more or less k-safe depending on your needs.
- K=0 means that if ANY node fails the cluster fails and your database will be marked offline for querying until that node is back online. If there was a hardware problem all you need to do is fix the hardware and upon reboot Vertica will begin the recovery process automatically. If you need to entirely rebuild the node from bare metal then you MUST ensure the new node has the SAME IP address. Vertica uses IP addressing, not FQDNs to refer to other nodes.
- K=1 means that any single node can be lost and the database will remain up (perhaps with performance degradation). This means that every node's data is "replicated" to at least one other node.
- K=2 means that your db can remain up if ANY 2 nodes fail. Here's where it gets tricky. If you WANT K=2 then your design must ensure that if 2 nodes fail that a third node must have your data.
The formula for K-safety is simple: to get K-safety you must have AT LEAST 2K+1 nodes.
So, to have a K-safety of 2 (in other words, you want to survive 2 nodes going down simultaneously) you must have AT LEAST 5 nodes. Vertica only officially supports K=2. For argument's sake, if you really wanted K=3 you would need 7 total nodes, minimum.
So, how does data get to the other nodes?
Unlike distributing data in SQL Server which ALWAYS requires DBA intervention (be it replication, log shipping, readable secondaries) everything is automatic in Vertica. You simply add a statement to the CREATE PROJECTION clause telling Vertica how to handle the sharding. You have 2 choices: 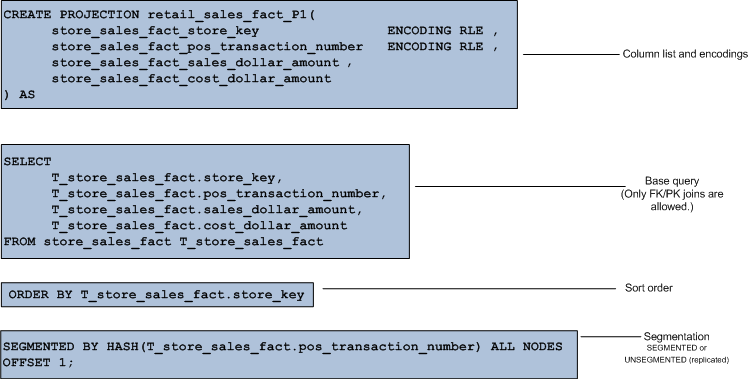
- When the projection is small and unsegmented it is replicated to ALL nodes. No need to add the overhead of segmentation in this case.
- When the projection is large and segmented then a "buddy projection" is copied to at least one other node. This is done using offsets. In the graphic to the right the fact table is segmented by a hash function to every node in the cluster.
OFFSET 1indicates that the buddy projection for a given node will be available on the next neighboring node in the cluster.
All of this k-safety stuff probably sounds complicated and it is easy to screw it up if you go off-the-reservation and do something that the Database 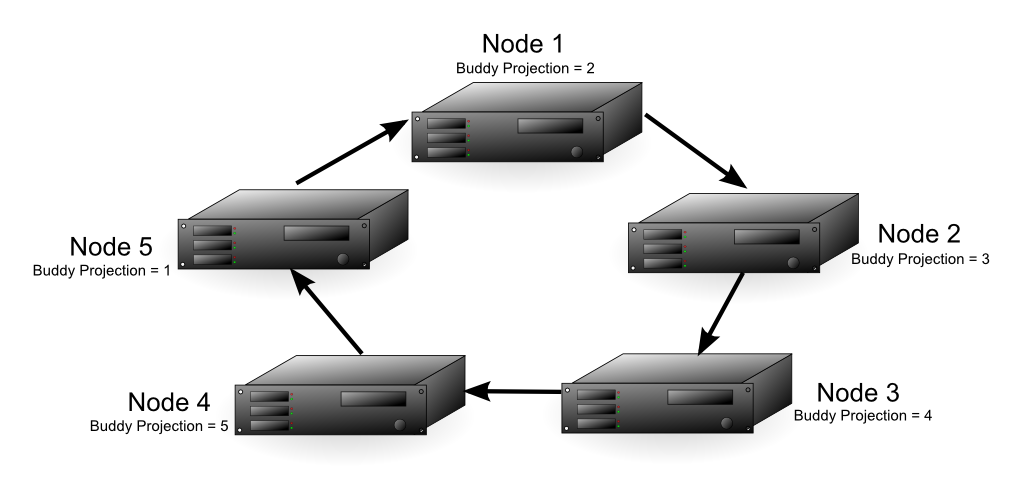 Designer did not recommend for you. Even if YOU think you should be at k-safety = 2, that doesn't mean Vertica agrees with you.
Designer did not recommend for you. Even if YOU think you should be at k-safety = 2, that doesn't mean Vertica agrees with you. SELECT current_fault_tolerance FROM system; will show you your current k-safety. If it isn't what you expected just rern the Database Designer.
Fault Groups
None of this K-safety stuff matters if all of your nodes are in the same rack and that rack loses power. This is a "correlated failure" and is a function of externalities. If this happens you certainly can't blame Vertica for your stupidity. In Vertica you can define your own fault groups to give Vertica hints to understand these correlated failure points better and influence its activities accordingly. For instance, defining a fault group will also let you smartly define control nodes. You wouldn't want all of your nodes to be in one rack and your control node to be connected to a different switch in a rack on the other side of your data center.
When half of your cluster nodes fail, your cluster fails, regardless of your K-safety. But it's common to have buddy projections on many nodes in your cluster. If possible it is best if those buddy projections/nodes have as little shared infrastructure as possible. Say for instance, SAN storage. If you have multiple SANs (or even VM hosts) you want those buddy projections to be as separate as possible for DR and performance reasons. Fault groups are the ticket for all of this.
What is the catalog?
When you install Vertica you must provide catalog and data directories and the path must be identical on all nodes. The catalog directory stores all of the metadata about your database; basically everything except your actual data. The catalog is akin to the PRIMARY filegroup in SQL Server although it  contains many files. It holds the system tables, data about your nodes, snapshots, file locations, etc.
contains many files. It holds the system tables, data about your nodes, snapshots, file locations, etc.
The catalog files are replicated to all nodes in a cluster whereas the data files are unique to each node. Vertica uses lots of files to store its data. Once a file is written to it is never altered, which makes recovery quite easy. Vertica simply needs to copy missing files to the recovering node from any other node with the necessary replicated data or buddy projections. Since files are never altered Vertica has no concept of FiLLFACTOR or PCTFREE. Since files are columnstores it is guaranteed that neighboring data will have the same datatype, therefore Vertica's abilty to encode and compress data is absolutely amazing. As mentioned in the last post, this becomes a challenge when deleting data. Since files are never altered Vertica uses "delete vectors" which are markers as to which rows in which files should be discarded during query execution. At certain intervals a background process will rewrite files to purge data that was deleted.
Summary
This post was a quick overview of Vertica's physical architecture. Hopefully you learned about some really cool features like buddy projections that guarantee that your data is safe even if you lose a few nodes. Let's say you are a SQL Server Guy, like most of my readers. You may be wondering why you would want to learn about Vertica if you have no plans to implement it. I find it fascinating to learn about competing technologies to help me understand limitations in the solutions I work with that I didn't previously understand. This makes us all a bit more well-rounded. In the next post we'll cover installing Management Console which is the GUI for Vertica.
You have just read "[[Vertica Physical Architecture]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
vertica