
Creating a Vertica Database
This is the next post in my Vertica series. In a previous post we covered [[Installing Vertica 7]]. I finished that post by mentioning that once you have a node installed you can connect and do basic tasks using /opt/vertica/bin/admintools. If you aren't familiar with Linux then even that simple command can throw you for a loop. Here is the exact process to start your exploration:
 Log out of Ubuntu if needed.
Log out of Ubuntu if needed. - Log in as dbadmin with your dbadmin password
cd /opt/vertica/bin./admintools
You should be presented with an "old-school console GUI". This will work over telnet or SSH and although it looks kinda like a Windows GUI you won't be able to use your mouse for anything. You navigate using Enter and the up and down arrows. You can poke around the menu options but you'll find you can't do anything with Vertica yet because we have not created any databases.
VMart
HP's sample database is called VMart. It is a data warehouse for a supermarket chain. Every installation of VMart is a bit different because the data is generated on-the-fly via a data generator. This makes query comparisons between Vertica installations a bit of a hassle vs something like AdventureWorks. HP also supplies a series of sample queries that demonstrate various Vertica features and can also be used for performance tuning with Database Designer. In this blog post we'll cover creating our first database by installing VMart.
Installing the VMart shell db
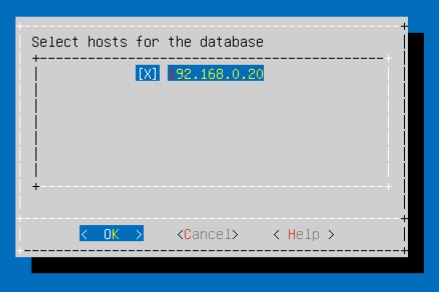 Start AdminTools
Start AdminTools- Enter "Configuration Menu"
- "Create Database"
- Call it "VMart"
- You will need to enter a password. This is equivalent to "sa" in SQL Server.
- You will need to select the hosts for this database. As mentioned in a previous post, Vertica nodes are named using their IP addresses. Since you only have one host currently you should see that host listed for this database. Click OK.
- Enter the catalog and data file locations. This will default to the home folder for your dbadmin user.
- You'll get a warning that a database with 1 or 2 hosts cannot be k-safe. That's fine, we'll fix that in a future post. Just click OK.
And that's it. You now have a shell database akin to the model database in SQL Server. At this point it is interesting to look first at the catalog and data directories. You'll end up with a structure similar to this:
| Folder | File | Purpose |
|---|---|---|
| /home/dbadmin | Home folder for dbadmin user | |
/VMart | folder containing your new VMart data | |
| dblog | contains the log file for the spread daemon, which is an open source messaging system not unlike JMS. Spread is used so individual cluster nodes can communicate with each other. | |
| port.dat | the port Vertica is listening on. nano port.dat will show you 5433 which is the default Vertica port. | |
/v_vmart_node0001_catalog | this is the catalog folder. You'll find various error logs and configuration files here. | |
| vertica.log | This, along with dblog, are the log files for your database. | |
/v_vmart_node001_data | this contains your data. This folder will have 0 files since we haven't created any data or schema yet. We'll come back to this later. |
This gives you an idea of what the file structures and naming conventions look like with a Vertica database.
Running the VMart scripts
With the VMart database created we need to create the schema and load the data.
 From the admintools Main Menu choose "
From the admintools Main Menu choose "2 Connect to Database". This will launch vsql which is similar to sqlcmd in SQL Server. We'll cover this in detail in a future post.- The VMart schema files are located in
/opt/vertica/examples/VMart_Schema. The README file show you various parameters to make a smaller or large sample data. You can view any of the files in that folder usingnano. We'll take a look at some of these files in more detail in a later post. For now we just want to install a base VMart db. - From vsql:
\i /opt/vertica/examples/VMart_Schema/vmart_define_schema.sql
\qto quit vsql, which will return you to admintools- Exit admintools.
cd /opt/vertica/examples/VMart_Schema./vmart_gen: this will create a small default db. What it really does is create a bunch of .tbl files in your folder. These files are pipe delimited text files that can be read using Vertica's COPY command, which is equivalent to SQL Server's bcp command.- We have the .tbl files that we now need to load into VMart. Run:
vsql -h <IP address> -d VMart -U dbadmin(this is an alternative method to launching vsql without launching admintools first). \i vmart_load_data.sql: this will load the .tbl files. This may take some time.
In the next post we'll take a look at the VMart schema, run some sample queries, and see how the data files are laid out on disk.
You have just read "[[Creating a Vertica Database]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
vertica