
Vertica Objects
It's been a few weeks since I covered any Vertica topics, the last being [[installing Vertica 7]] . Before we create our first Vertica database it's important  to understand the core Vertica objects that we will eventually interact with. Remember that Vertica data is stored in a column-oriented manner. It is optimized for read-only data warehouse-style applications.
to understand the core Vertica objects that we will eventually interact with. Remember that Vertica data is stored in a column-oriented manner. It is optimized for read-only data warehouse-style applications.
Logical Modeling
You do your logical modeling just like you would on any other relational platform. Vertica is relational, not hierarchical or network-modeled. From a physical implementation perspective, It has schemas, tables, views, RI constraints, etc that are all visible to your SQLers. There's no reason why a good data warehouse schema (star schema) that you would concoct for, say, SQL Server or Oracle, wouldn't logically be the same on Vertica.
Physical Modeling
The difference with Vertica and other RDBMSs is at the physical modeling layer. Physical modeling is quite a bit different than what you may be accustomed too. "Tables" are physical storage objects in the relational world. With Vertica a "table" is a collections of table columns called projections. Every table must have at least one projection that stores all of the table's columns' data. This is called a superprojection. Every table has one and only one superprojection.
As mentioned above, you have schemas, tables, and constraints. What you don't have is indexes. Instead of indexes data is materialized directly into the necessary projections.
More on Projections
So, remember that projections are really just groups of columns. Almost everything we do in Vertica revolves around a projection.
More simplistically, a projection (any projection) is persisted data, usually optimized. Projections are not always raw data like in an RDBMS table (but it 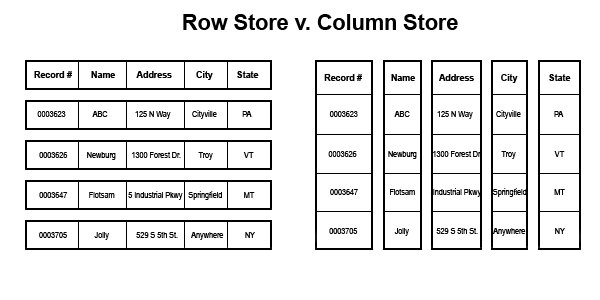 is if it is the superprojection). Instead, a projection is more like a materialized view or a saved result set. It is optimized for reads and is automatically updated as data changes. Vertica can encode and compress the data in projections since like data types are always stored next to each other. Note that in the graphic to the left that the Name "column" is physical stored together and is the same data type. This will encode and compress quite nicely.
is if it is the superprojection). Instead, a projection is more like a materialized view or a saved result set. It is optimized for reads and is automatically updated as data changes. Vertica can encode and compress the data in projections since like data types are always stored next to each other. Note that in the graphic to the left that the Name "column" is physical stored together and is the same data type. This will encode and compress quite nicely.
Just like a SQL Server partition or index, you don't query a projection directly (or a superprojection...from now on when I mention "projection" you can assume either a projection or superprojection unless I specifiy otherwise), you query a table. Vertica picks the best projection for you just as SQL Server would pick the best index for you.
Think of a projection just like a SQL Server indexed view or an Oracle materialized view. It is legal to put just about anything in a projection that you would put into an indexed view. You can join tables/projections (but only on PK/FK cols and only as INNER JOINs...these are called pre-join projections), calculations and aggregations (as of a new feature in Vertica 7)...you can even put ORDER BY clauses which you can't generally do in a view in SQL Server. In fact, this is very much preferred.
When modeling a projection, store columns together that are regularly accessed together to optimize IO. This is called a column grouping.
One exception that may seem odd at first is that a projection CANNOT have a WHERE clause. The reason is quite simple. Remember that a  projection is really just a set of materialized columns. You can't filter the columns otherwise the projection isn't a true representation of the underlying table. To overcome this the conventional Vertica wisdom is to ensure that often-used predicates are contained in leading columns of your projections.
projection is really just a set of materialized columns. You can't filter the columns otherwise the projection isn't a true representation of the underlying table. To overcome this the conventional Vertica wisdom is to ensure that often-used predicates are contained in leading columns of your projections.
Segmentation
Small projections (lookup tables for instance) are replicated to every node in your cluster. They are not segmented, they are unsegmented projections.
Large projections are segmented (similar to SQL Server partitioning, or maybe the better analogy is "sharding" which SQL Server does not have natively) and the segments are smartly copied to other cluster nodes for redundancy and peformance.
Segmentation is handled by built-in hashing and there are multiple algorithms available to you to do this. The "segmentation key" should have a high cardinality (like PKs) to be efficient otherwise the data will be skewed to certain segments/nodes. You will never achieve perfect segmentation so some skewing will always occur. No need to over-engineer this.
In the next post I'll cover how segmentation and hashing and something called "buddy projections" ensure that your data is smartly copied to other nodes to increase availability, recoverability, and performance.
Table Partitioning
Vertica also has table partitioning. Conceptually this is similar to SQL Server's partitioning. Partitioning simply divides a large table into smaller pieces. It applies to all projections for that table. Partitioning is generally used for fast data purging and query performance. It will segregate data on each node. Partitions can be dropped quickly and switched in and out just like SQL Server.
DELETEs (and UPDATEs which are really DELETEs followed by INSERTs) are cumbersome for a columnstore like Vertica. In a rowstore a given row is generally physically contiguous on disk. Not so with a columnstore. Therefore Vertica handles this by using delete vectors which are simply markers that a row(s) should be removed from any result sets. This means that data can be as compact as possible on disk without any risk of fragmentation. There are background "Tuple Mover" processes that actually rewrite the underlying files (projection data) to remove deletes. Therefore, it's best to avoid DELETE processing as much as possible and this is where smart partitioning can help.
So, other than as an alternative to deleting large chunks of data, what is the purpose of table partitioning? Same as SQL Server. If your query is written correctly you can benefit from "partition elimination" where Vertica does not even need to scan a given partition if it knows none of that partition's data will qualify for the result.
Partitioning and Segmentation Working Together
Segmentation is defined on the projection and is used to gain distributed computing in Vertica. That is its sole purpose. Different projections for the same table will have identical partitioning but can be segmented differently. Partitioning is declared on the CREATE TABLE statement. Segmentation is declared on the CREATE PARTITION statement.
Views
Vertica has the concept of a view or a saved query. A view will dynamically access and do any necessary computations from the underlying data at execution time. Unlike a projection, a view is not materialized and stores no data itself. A view does not need to be refreshed, unlike a projection, whenever underlying table data changes. A view can reference tables (and temp tables) and other views. Unlike most relational products, views in Vertica are read-only.
Licensing and Projections and Segments
When you use the Community Edition of Vertica you only get 3 nodes and 1TB of data. The definition of "data" is important since you can have a small amount of base table (superprojection) data but tons and tons of projections. Data, in terms of licensing, is the base table data ONLY. If you begin to run low on available space (in a future post I'll show you how to determine this and stay in license compliance) you can always drop partitions or delete data.
Summary
In a future post we'll actually get to work hands-on with all of this stuff. For now I think it's just important to understand key Vertica concepts and how they compare with SQL Server.
You have just read "[[Vertica Objects]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
vertica