Metadata Driven Database Deployments (MD3) is my build-and-deploy mechanism for SQL Server-based applications. Check out the other posts in my  MD3 blog series. In the last post (Why do we need another database deployment tool like MD3?) I covered some reasons why database deployments give DBAs and developers fits. In a nutshell, it's because we write too much hand-crafted DDL.. Even when we use third-party GUI tools to manage our deployments we still hit edge cases where the migration isn't smooth. So why are schema changes so difficult?
MD3 blog series. In the last post (Why do we need another database deployment tool like MD3?) I covered some reasons why database deployments give DBAs and developers fits. In a nutshell, it's because we write too much hand-crafted DDL.. Even when we use third-party GUI tools to manage our deployments we still hit edge cases where the migration isn't smooth. So why are schema changes so difficult?
Database Object State and Builds
When you "build" your Java app (...or C# or whatever...) you are really just compiling the code on your machine. If compilation is successful then you can rest assured that it will compile on, basically, any machine (OS and processor architecture might be exceptions). The
deployment is simply a matter of copying your compiled code. In the .NET world you usually build a Windows Installer package or perform an "xcopy deployment". Build and deploy is really easy, as is building the necessary "CI loops" (...they run your unit tests...) to ensure your builds aren't broken when a developer checks in a change.
Databases work differently. Just because your scripts compile and deploy on your machine/database does not mean they will deploy anywhere else.
Why?
Java code, when it compiles, couldn't care less about the "state" of the previous build. The code is “stateless”. Some database code, on the other hand, is “stateless” while some is “stateful”. Database developers need to worry about “history”, or "state", which is the existing data in the tables that must be maintained into the next release. The code must do more than just compile, it must be respectful of existing data. And data isn't the only stateful database object. You don't want to recreate a bunch of indexes needlessly either.
| Stateless Objects | Stateful Objects |
|---|
| Views | Tables/columns |
| Procedures | Indexes |
| Functions | Constraints (PKs/FKs/CHECK) |
| Model Data (sometimes called seed/lookup/master data). An example is a list of states and abbreviations. This data rarely changes and when it does it changes via an approved process (ie, a Master Data Management update) | Model Data (if the data can be altered by the customer. An example is order status codes. If you allow your customer to change (or add to) their model data then you don't want to "reset" their model data with your updates...or...maybe you do depending on the scenario. |
Stateless Object Patterns
Stateless db objects are the easiest to deploy...you simply compile them. You do not care about what the previous version
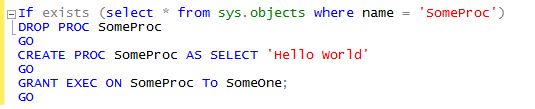
of the object looks like, you simply create the new version, overwriting the old. Just like you would overwrite the last Java build with the current one. Traditionally you code stateless objects using a pattern
similar to the graphic to the right.
Since the object, in this case a stored procedure, is stateless we can simply drop it and re-create it. When doing that we lose our permissions so we must re-apply them. It would be nice if we had the [[CREATE or REPLACE pattern for Transact SQL]]
like Oracle does. CREATE OR REPLACE is simplified syntax that obviates the need for re-applying permissions and checking if the object 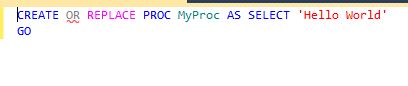 exists. Oh well...maybe in the next replace of SQL Server.
exists. Oh well...maybe in the next replace of SQL Server.
Generally you should deploy your stateless objects near the end of your deployment. There are some exceptions to this rule:
- You may have object dependencies which require certain stateless objects to deployed in a specific order. For instance, if viewA references functionB which in turn references viewC then you have to ensure those objects are applied in a certain order.
- if you have
SCHEMABINDING applied to any of your objects and you try to first manipulate a stateful object (such as a table) you'll need to drop the object with the SCHEMABINDING clause first.
MD3 handles all of this for you and in the demo files I give examples of this and how it is very simple to handle these edge cases.
Stateful Objects and Patterns
As mentioned before, Java has no "stateful" code...if the code compiles you are good...if it doesn't compile you have problems. In the database world it is the stateful code that causes database developers fits.
An example of "stateful" database code that can be maddening is index DDL. Let's see why that is.
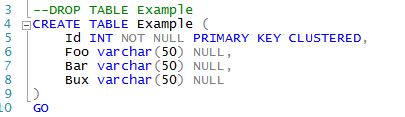
You can download the example code here. We start by creating a very simple table with a few columns. Most developers just create their tables and then either worry about the indexes later or let the DBAs worry about it when performance becomes a problem. At a later time the developes realize that they need to add an index to the Foo column. If you are using a tool like Visual Studio db projects then you can use very simple
CREATE INDEX syntax. Otherwise you need to do an "existence check" to ensure that a subsequent execution of your script won't generate an "object already exists" error.
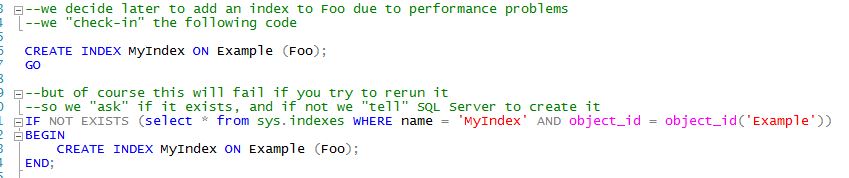
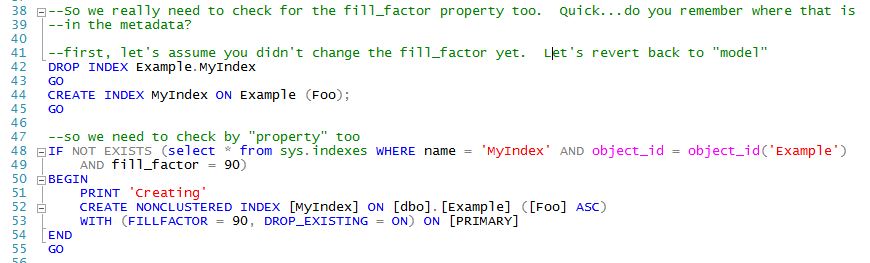
The "existence check" syntax isn't terribly difficult to handle...yet. Now let's say you notice a lot of page splitting and realize that your table design and data access patterns indicate that you need to change the fillfactor to 90. Quick...do you remember where the fillfactor settings are stored in the metadata tables so you can modify the "existence check"? You could just code up something quickly like this:
The problem is that you will drop and recreate the index at every deployment. Again, a tool like VS db projects will obviate the need for this. Better "existence checking" code would be something like this:
Our code is getting a little more "advanced" and much more "hand-crafted" than I am comfortable with.
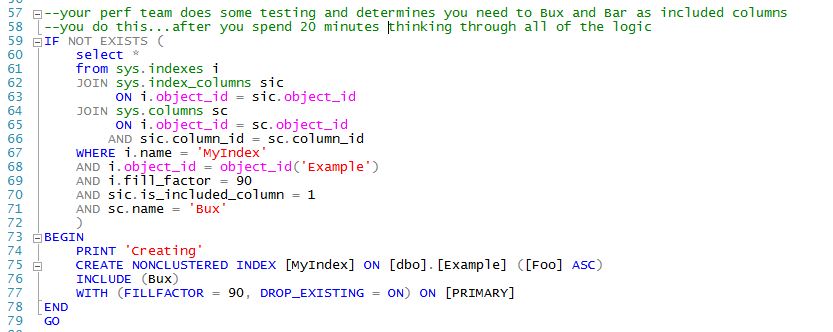
Here's a common scenario...once your index is released to production your DBAs notice that you have a bunch of Bookmark Lookups causing customers to report application slowness and they believe that they should add a couple of included columns to your index. The DBAs are nice enough to tell you that they've done this and that you need to make this new index "model code". You determine this is the new index creation code you need:
Yikes! That's getting to be really complicated code.
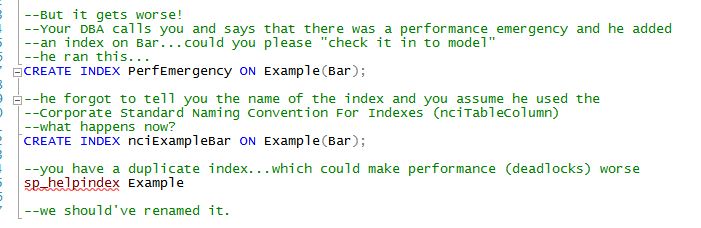
Here's a slightly different example. Your DBA calls you and tell you that he saw a gigantic "blocking storm" and needed to add an index on the Bar column. You agree with his analysis and you both decide to make this a model index. The first block of code is what the DBA added (note the index name doesn't follow your naming conventions) and the second block is the code you made "model". Do you see the problem?
You really should've renamed his index, if his index exists. Now you risk a duplicate index during a deployment.
A Better Way to Handle Stateful Objects
DDL is kinda esoteric and difficult to remember, as seen above. DML for master/seed/model/system data that you may need to deliver is similarly complex (we'll look at this problem later). In MD3 DDL is much simpler. Wouldn't it be nice if you could just enter the "properties" of the desired object in a metadata table and SQL Server just did what it needed to do to make that object for you? MD3 does that for you. Here's a screenshot that shows how to add an index to the HumanResources.Department table:
Pretty simple. We have a metadata table called MD3.Indexes that looks VERY similar to sys.indexes. We "declare" our new index with its desired properties right into that table, then we run MD3.
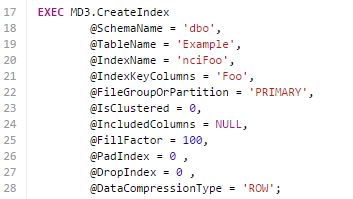
Now let's say you want to alter that index to change your compression settings from NONE to ROW...just update the entry in MD3.Indexes and rerun MD3. Need to add an Included column? Change the NULL above to the name of the column you want to include and rerun MD3. Maybe the index is no longer needed...just change the DropIndex column to 1.
Under-the-covers MD3 is simply cursor-ing over the metadata table (MD3.Indexes) and determining if there is any work to do (more on how this is done in the next section). It does this by calling the MD3 stored procedures that do the actual work...for instance, EXEC MD3.CreateIndex. You can call these procedures and use them yourself without using the MD3.Indexes metadata table. Here's an example call that creates nciFoo. Let's say you decide to change this index to have a FillFactor of 90...how do you think you would do that? That's right, change the parameter and run the procedure. Want to change the filegroup (or partition)...take a guess at the process? No complex hand-crafted DDL is required.
 So the question is...how does MD3 actually build the DDL under the covers and what makes it so much better than hand-crafted DDL? MD3 uses The Four Rules.
So the question is...how does MD3 actually build the DDL under the covers and what makes it so much better than hand-crafted DDL? MD3 uses The Four Rules. We'll cover [[MD3 and The Four Rules]] in the next post.
You have just read "[[MD3 and "state"]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed.