
MD3 and The Four Rules
In the last few posts I covered what MD3 is ([[Introduction to Metadata Driven Database Deployments|Metadata Driven Database Deployments]]) and why it is better than hand-crafted DDL. In this post we are going to cover The Four Rules of Database Deployments. Regardless of whether you decide to use MD3 or not, if you understand The Four Rules your database deployments will run much smoother.
to cover The Four Rules of Database Deployments. Regardless of whether you decide to use MD3 or not, if you understand The Four Rules your database deployments will run much smoother.
Some Background
In the last post ([[MD3 and "state"]]) we covered a scenario where we had to write really complex DDL if we wanted to deploy an index change properly. We need an index, called
MyIndex, created on dbo.Example with a fill_factor of 90, on column Foo, with included_column Bux. Here is the DDL: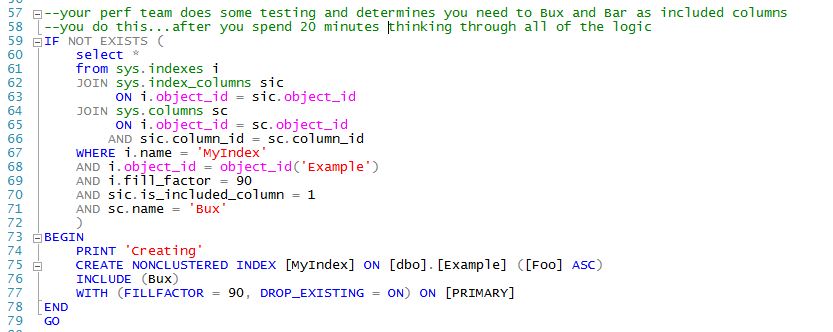
DDL is kinda esoteric and difficult to remember, as seen above. DML for master/seed/model/system data that you may need to deliver is similarly complex (we'll look at this problem in the post [[MD3 Model Data Patterns]]). In MD3 DDL is much simpler. We just "declare" the properties of our object and let MD3 determine what needs to be done to get us to "model". Basically, we enter "metadata" about our object into an MD3 table (for instance
MD3.Indexes), which looks very similar to the "sys" system tables (in this case sys.indexes). Here's a screenshot that shows how to add an index to the HumanResources.Department table: 
 Pretty simple. We have a metadata table called MD3.Indexes that looks VERY similar to sys.indexes. We "declare" our new index with its desired properties right into that table, then we run MD3. Under the covers MD3 is making calls to
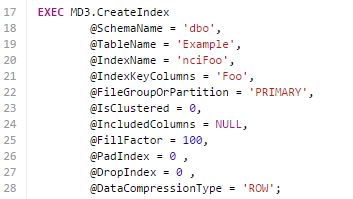
Pretty simple. We have a metadata table called MD3.Indexes that looks VERY similar to sys.indexes. We "declare" our new index with its desired properties right into that table, then we run MD3. Under the covers MD3 is making calls to MD3.CreateIndex (which you can call instead of populating the MD3.Indexes table) similar to the nearby graphic that is adding the index nciFoo to dbo.Example. Each parameter to
MD3.CreateIndex (and each column in the MD3.Indexes table (see above screenshot) is a metadata property that we can declare for an index. These properties cover just about every option you can think of regarding an index. There are some properties missing...for instance, there is no option for filtered indexes because I've never really found a good use case in my career where I absolutely needed a filtered index. Since MD3 is open source you could always add this functionality if you needed it. Here are some other index properties that are missing and why:| Index Property | Why it is missing? |
|---|---|
| WHERE <filter predicate> | filtered indexes. You can always add this yourself. |
| IGNORE_DUP_KEY | I've never found a good use for this option. |
| STATISTICS_NORECOMPUTE | I've never found a need for this. |
| DROP_EXISTING ON|OFF | MD3.CreateIndex will smartly determine if this should be set to ON or OFF based on what is being asked. |
| ONLINE = ON|OFF | MD3.CreateIndex will determine whether this option should be used or not for you, based on whether the index follows the rules for ONLINE index creation. Here is another case where MD3 is a huge help. |
So the question is...how does MD3 actually build the DDL under the covers and what makes it so much better than hand-crafted DDL?
The Four Rules of Stateful Object Deployment
If you always follow The Four Rules when you code your DDL you will always have a successful deployment (no failures!) and you will never do unnecessary DDL. MD3 does all of this for you. Assume you have some DDL that you need to apply:
- if the object exists by name and by "properties", then silently continue, there is no work to do. In other words, there was no change in the object between deployments. The "properties" are the parameters to the
MD3.Createprocedures (see the screenshot above). - if an object exists with the same “properties”, but the name is different, then RENAME the object. Example: I have an index with the same column list, order, fill factor, on the same filegroup, with the same compression, etc...but it is named differently. All MD3 does is run
sp_rename. This scenario occurs, for instance, when your DBA adds an emergency index to a table and you check in the same index structure, but you use your naming conventions. - if the object exists by name, but the "properties" are different, ALTER the object accordingly. Example, you have an index with the same name and mostly the same properties, but you need to change the INCLUDED col list and FILLFACTOR. MD3 handles this without esoteric, hand-crafted DDL. Usually an ALTER can bring the current object up to the desired properties, otherwise DROP/CREATE is used. The most important thing to remember is that YOU don't have to code the DDL and worry about covering all possible scenarios.
- Else, CREATE object with properties as defined. At this point MD3 realizes this is a missing object and creates it according to your declarations.
If you don't do The Four Rules correctly you risk, at a minimum, recreating expensive objects at every deployment. You don't need MD3 to do a DDL deployment, but it makes it a lot easier and less error-prone.
An Example
Let's take our example code again and determine what MD3 will do in various situations regarding The Four Rules. The below table is kinda like the "unit tests" for
MD3.CreateIndex (tsqlt unit tests available on request). | Database State | Expected Result | Why? | Covers which of The Four Rules |
|---|---|---|---|
dbo.Example table does not exist | FAILURE | This scenario will be caught during continuous integration testing and will never happen during a production deployment. (See [[Continuous Integration Testing with MD3]]) | None. |
index nciFoo does not exist | Index created | The index will be created with the declared properties. | 4 |
An index exists called dbaFoo with the same properties | Index renamed | The index will be renamed using sp_rename to nciFoo. This ensures that a duplicate index is not created with the same properties. | 2 |
nciFoo exists, but with different "properties" than what is declared | Index altered | When possible the index will be ALTERed. Otherwise the existing index will be dropped and the desired index will be created. In some cases, depending on what is being changed, an index cannot be ALTERed. | 3 |
nciFoo exists with identical properties | Silently continue | There is no work to do. | 1 |
Summary
 In this post we looked at The Four Rules of stateful database object deployments. If you follow The Four Rules when you deploy your objects you will find that you have fewer errors and more reliable, repeatable deployments. You don't have to use MD3 to use The Four Rules. You can use any tool, even plain 'ol DDL. MD3 just makes everything a whole lot easier.
In this post we looked at The Four Rules of stateful database object deployments. If you follow The Four Rules when you deploy your objects you will find that you have fewer errors and more reliable, repeatable deployments. You don't have to use MD3 to use The Four Rules. You can use any tool, even plain 'ol DDL. MD3 just makes everything a whole lot easier. In the next post, [[The Other MD3.Create Procedures]], we'll cover how The Four Rules are applied to other stateful database objects. In a later post we'll cover how [[MD3 Model Data Patterns|MD3's model data patterns]] work with The Four Rules to ensure your model/system/lookup data deployments work just like your other stateful object deployments.
You have just read "[[MD3 and The Four Rules]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 sql server data architecture