
Why do we need another database deployment tool like MD3?
This is the next post in my MD3 series (Metadata Driven Database Deployment). MD3 is my build-and-deploy system that I've evolved over the past 15 years. Quick history...I worked at an ISV and we supported 4 versions of our software (Version X back to Version X-3) and we needed to support upgrading any of those versions to "current". We had about 40 customers with the average db size ~40GB. To make matters even more complicated we supported either SQL Server or Oracle. Both had the same schema...mostly.
| Quick Links |
|---|
| [[Introduction to Metadata Driven Database Deployments]] |
| Download MD3 (with samples) |
| Documentation on CodePlex/git |
| Presentation on MD3 |
| Other Posts about MD3 |
| AdventureWorks2013 reverse-engineered into MD3 (takes 5 mins to do with ANY database) |
So we needed a tool to upgrade a database reliably without having non-database developers writing complex, error-prone, hand-crafted DDL. Most of our data developers knew Oracle or SQL Server, but few knew both. I learned a lot about what works and what doesn't when upgrading a database in a complex data environment like this. I created a database CI loop ([[Continuous Integration Testing with MD3|also included with MD3]]) before CI loops were sexy and ubiquitous. Every day we tested our db scripts against real customer databases and ensured everything upgraded and functioned properly. We never worried about the actual customer production upgrade event because our CI loops already upgraded the customer hundreds of times (albeit on older, stripped, and scrubbed databases).
I've deployed versions of this tool at many different employers and clients. Each has been radically successful.
 The developers love how easy it is to make schema changes without hand-crafting DDL. It is totally flexible and customizable to whatever you need.
The developers love how easy it is to make schema changes without hand-crafting DDL. It is totally flexible and customizable to whatever you need.- DBAs and app admins love it because it is scriptable, has customizable logging, and show the SQL that is being executed. Nothing is hidden from the DBA.
- Management likes the fact that it requires zero training and creates a repeatable, reliable process.
The latest incarnation, which I haven't yet open-sourced, is a version that will do a near Zero Downtime database upgrade. Contact me if you might be interested in this.
Why do we need another database deployment tool?
- Modifying a table's schema requires you to "port" the old database structure to the new one. And also the data. This is fraught with danger. Perhaps each version of the table has also experienced schema changes which you also need to take into consideration. You have to then change keys (both primary and foreign) and clustering as well as all of the non-clustered indexes. What if each customer/version has a different set of indexes and keys?
- Then you need to modify each database object that accesses the table. All of your stored procs, functions, and views. Then you need to modify your Java (or C# or whatever). All of this scares the average database developer.
- Since this is a large table how can we guarantee this won't cause our customer excessive downtime while we migrate the data? How do we verify the customers' data afterwards?
 ever-changing business rules. One of the primary reasons the NoSQL movement (whenever I hear this I think, "technology or bowel?") grew, especially document and keystores is because they touted the fact that their technologies allowed you to modify your schemas without needing to worry about modifying all of that data access code that scares us all. And there was no need to "port" the data from old-to-new schema.
ever-changing business rules. One of the primary reasons the NoSQL movement (whenever I hear this I think, "technology or bowel?") grew, especially document and keystores is because they touted the fact that their technologies allowed you to modify your schemas without needing to worry about modifying all of that data access code that scares us all. And there was no need to "port" the data from old-to-new schema. 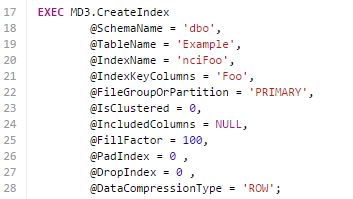 (and you can review them) to get your schema to that destination. Here is a simple example. Assume we have a table named
(and you can review them) to get your schema to that destination. Here is a simple example. Assume we have a table named dbo.Example and we decide a non-clustered index on Foo would be beneficial to performance. See the nearby graphic to see how easy this is with MD3. (Actually, the command is even easier than that, and I'll show you that in the next post.) But MD3 gets even better. Let's say a DBA already noticed a performance problem and indexed Foo already but named the index dbaFooPerfProblem. In that case the index will be renamed. You won't get a duplicate index. Let's say later you decide to make nciFoo into a compound index with Foo,Bar as the keys. Simply changing Line 21 to 'Foo,Bar' will automatically change the existing nciFoo, if it exists, or build a new nciFoo with the declared properties, if it doesn't exist. You have just read "Why do we need another database deployment tool like MD3?" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
sql server md3 data architecture