

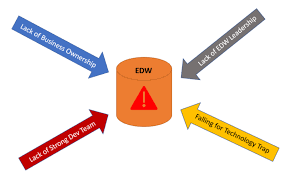
Why your EDW projects fail
Does your current data ecosystem provide actionable intelligence and predictive capabilities?
 Are you convinced that your current data strategy can grow your business?
Are you convinced that your current data strategy can grow your business?
If you had access to more data, how would you use it?
Do you really know why you need a data lake and what makes it different from your data warehouse?
My clients come to me with data problems they haven’t been able to solve. They start, or expand, “data warehouse” projects every 5 years, and each one is a struggle. Does this sound familiar?
I know why your data warehouse projects are at-risk:
- too much time is spent doing data modelling and making star schemas
- time and money is sunk into ETL (copying data around)
- during that time the “questions” you need your data to answer have changed and the data model and ETL do not support the new questions
- Your warehouse is loaded nightly but you need it real-time, and your staff can’t make that happen
- data warehouses are backward-looking and you need to predict what will happen tomorrow
I know how to avoid these problems.
Why the high fail rates?
Data projects have a high fail rate during the modeling and ETL phases. This is a yearlong process where you aren’t showing value to your stakeholders. With the cloud, and my methods, there is less dependence on modeling and NO ETL, so you show value faster.
I avoid ETL and modeling work until I am sure your data answers the questions you have. Then I show you how to take the data and structure it for your users. You soon feel confident that you can do your own exploration on your data after I leave. Since I iterate quickly there is less risk and no need for huge upfront capital outlays.
Not convinced this methods work? Read my Case Studies ›
Sounds good, but we’ve heard this before. HOW do you do this?
Start by using the public cloud, generally Azure.
It’s fast to setup and learn and doesn’t require the huge investment needed for an on-prem data warehouse that might ultimately fail. Even if you ultimately want the solution to live in your data center, by using the cloud you can iterate quickly without waiting on your infrastructure team to set up servers.
Avoid ETL
How? We think of your data as “streams” instead of just tables in a database somewhere. We’re creative, and we can usually get the data you need in real-time, sometimes without touching your database. Most importantly, we don’t “transform” data, which always has the unintentional side-effect of causing the data to lose its meaning and value.
We put this streamed data into something called a “data lake” where we can begin to explore the data with you.
What is this “data lake” thing?
Quite simply, it’s a place to store data in its rawest form, optimized so you can run analytics on it, without needing to “transform” it first (that’s ETL) to get it into a structure that your star schema requires (that’s data modelling).
Customers realize that their “questions”, that they thought they needed a data warehouse for, can be answered in Azure using tools they already know and love, within DAYS. Customers with an existing data warehouse can take this enriched “data from the lake” and copy it to their warehouse. Using this approach the time-to-market is staggering.
But why data “streams”?
Our customers realize that their Data Lake has answered questions that they’ve never been able to answer with their existing  data warehouse. They begin to spot patterns in the data events. They wish they could spot those patterns in the data in realtime to take action faster, or predict what will happen next. But you can’t do that with a data warehouse that is loaded nightly. But you can “listen” on the data stream for those events and take immediate action.
data warehouse. They begin to spot patterns in the data events. They wish they could spot those patterns in the data in realtime to take action faster, or predict what will happen next. But you can’t do that with a data warehouse that is loaded nightly. But you can “listen” on the data stream for those events and take immediate action.
That’s the power of thinking of your data as unbounded ‘streams’ and not as tables in a database. That’s the Digital Transformation.
But I’m happy with my data warehouse. Do I need to replace it with a data lake?
We never “rip and replace”. The concepts I bring to your data projects are nothing new and aren’t dependent on building a data lake. In some cases a data lake may be overkill. At a minimum these are complementary technologies. If you struggle with ETL or adding new “facts” to your existing warehouse, then I have solutions that will get you results faster.
“Isn’t a Data Lake really just Hadoop? We can’t afford to undertake a Hadoop deployment.”
A “data lake” is simply a method that allows you to do analytics without data modelling and ETL. Hadoop is merely one way to implement a data lake. But you can implement a data lake in the cloud without using Hadoop or needing to hire Hadoop talent. I’ve implemented conceptual data lakes for YEARS on SQL Server. It’s not quite as fast or easy and it still requires a modicum of ETL effort, but it can certainly be done.
So really, what is the difference between a data lake and a data warehouse and why do I need both?
After an hour or so customers understand why a data lake has advantages over a EDW. The next reaction is usually, “let’s rip  out our EDW and just use the data lake, it’s less data redundance.” It, unfortunately, doesn’t work that way. Data lakes are great for exploratory data sandboxing, but rarely will a data lake be able to serve the operational report and dashboard data you need in a performant manner. Although I have done this on occassion, it usually makes more sense if thse technologies are complementary.
out our EDW and just use the data lake, it’s less data redundance.” It, unfortunately, doesn’t work that way. Data lakes are great for exploratory data sandboxing, but rarely will a data lake be able to serve the operational report and dashboard data you need in a performant manner. Although I have done this on occassion, it usually makes more sense if thse technologies are complementary.
Data Science
Do you employ data scientists? Are you thinking about it? Are your data scientists productive? Are they frustrated because they can’t get the data they need? These problems are also solved by the use of a data lake where I can structure the data how the consumer needs it.
I know how to make data scientists productive. A data scientist spends 80% of her day doing “data wrangling”. Data wrangling is the fancy way of saying “ETL”.
Think about that…you are paying your data scientist to transform data that you already paid your ETL Developer to transform so it was ready for your data scientist!!! If that sounds unproductive then you are starting to see why I avoid ETL on my projects.
Your data warehouse, quite simply, is a view of your existing data, optimized for reporting. But that view is not conducive to data science. A data lake is a different view of some of the same data … a view that is much easier for your data scientists to consume. Data scientists need that raw data lake data before it gets “transformed” into a database and loses some of its meaning.
And when your staff has a valuable, predictive model from the data in the lake, I can show you how to apply that model to your data “streams”. Quickly. Now you are making realtime predictive analytics.
This “data lake” stuff sounds like Big Data, but we don’t have a Big Data Problem, we have a Small Data Problem
I don’t like the term Big Data. The cloud, and concepts like “streams” and “data lakes”, work equally well with Petabytes or Megabytes of data. I’ve saved failing data projects for small datasets using these concepts.
You may not have Big Data, but you probably do have Fast Data, or questions that you need answered quickly.
This is what we hear from our customers, every day:
“It costs too much to expand our EDW.” “We have data but we don’t know how to do analytics on it” “We don’t have a 360 degree view of our customer/supplier/patient” “We’d like to integrate social media but don’t know how” “We built an EDW but it doesn’t answer our questions” “I wish we could do predictive analytics in our EDW” “We can’t afford Data Scientists and expensive Hadoop Engineers”
I help me customers solve these problems using the Azure Data Platform and the concepts mentioned above. I live and breathe this stuff. I give presentations and seminars on these topics.
Does that sound like a partner you can trust?
Thanks for reading. If you found this interesting please subscribe to my blog.
Related Posts
- Do This Before You Outsource Your Next Analytics Project
- altdata Ideas You Can Leverage Today
- Convert Databricks DBC notebook format to ipynb
- Case Study: Data Analytics in FinServ
- Why your EDW projects fail
Dave Wentzel CONTENT
data architecture sql server etl cloud data lake case study