
The OO Design Principles of MD3
Over the last few posts we've covered how [[Introduction to Metadata Driven Database Deployments|MD3]] handles stateful database object  deployments. You may still be wondering why you should care about deploying your database code using metadata instead of hand-crafted DDL. In this post I'm going to take a detour from the technical aspects of MD3 and instead cover the design principles behind MD3 that are not found in (m)any other database deployment tools. Even if you decide MD3 isn't for you you may learn a few things that help you become a better data developer.
deployments. You may still be wondering why you should care about deploying your database code using metadata instead of hand-crafted DDL. In this post I'm going to take a detour from the technical aspects of MD3 and instead cover the design principles behind MD3 that are not found in (m)any other database deployment tools. Even if you decide MD3 isn't for you you may learn a few things that help you become a better data developer.
 I designed MD3 to follow standard Object-oriented design principles...using TSQL. I haven't always succeeded, but the OO principles in MD3 make it so much more robust and reliable than standard DDL. Let's cover a few of these principles, starting with the most important first (IMHO).
I designed MD3 to follow standard Object-oriented design principles...using TSQL. I haven't always succeeded, but the OO principles in MD3 make it so much more robust and reliable than standard DDL. Let's cover a few of these principles, starting with the most important first (IMHO).
"Tell, Don't Ask"
...is a object-oriented programming principle that helps programmers remember that they should strive to tell their functions what to do rather than ask them what their state is, then ask them to perform some action based on that. We need more of this in SQL and DDL. Procedural code, such as DDL, does far too much "asking" for information and then making decisions based on the response. It would be nice if us database developers could just tell our RDBMS what we wanted and the RDBMS would just "do the needful" and make it so.
Here's an example of some code that probably looks familiar to you...it builds an index if it doesn't exist:
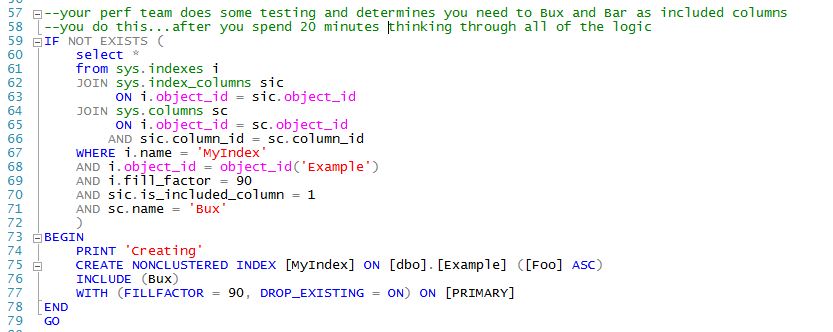
This is an example of "Ask, then Tell" which is terrible. As data developers we write code like this because we need to ensure the index doesn't already exist before we create it. This is a code pattern that you have to remember and may only use a few times a year. Variants of this code will be scattered in tons of index creation scripts. All we really should need to do is "tell" our RDBMS what the index should look like and the RDBMS should be able to figure out how to get us that index in the most efficient manner possible. I call this "declarative DDL". This is what MD3 does for you. This graphic shows how MD3 handles index creation declaratively. Very simple...we tell MD3 what our index should look like and it ensures that after EVERY deployment we get an index called nciFoo with the declared properties. It doesn't matter if this is a "net new" database, a database updated from a 5 year old version of our application, or a database upgraded from yesterday's build.
DRY Principle
Index creation DDL with an "if exists check" also violates the DRY Principle (Don't Repeat Yourself). As mentioned before, you may have variants of that code in lots of sql scripts. Let's suppose you need to modify all of those scripts because you decide to implement ROW compression? You may need to change HUNDREDS of scripts. If you use MD3 you simply modify MD3.CreateIndex to default all indexes to use ROW compression. Very easy! Change one script instead of hundreds.
| Quick Links |
|---|
| [[Introduction to Metadata Driven Database Deployments]] |
| Download MD3 (with samples) |
| Documentation on CodePlex/git |
| Presentation on MD3 |
| Other Posts about MD3 |
| AdventureWorks2013 reverse-engineered into MD3 (takes 5 mins to do with ANY database) |
So why do the ANSI SQL standards not specify a Declarative DDL syntax like this? Probably because the ANSI standards don't specify concepts like "indexes" and "clustering keys" and "fillfactors". DDL is, in fact, declarative in that you "declare" things like column names and data types, but the process to implement those changes is still a series of imperative verbs that carry out those actions (ie, CREATE and ALTER). The ANSI specifications allow the "hows" to be vendor-implementation-specific. And, of course, SQL and DDL were created before object-oriented programming became de facto.
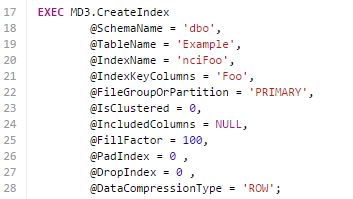
So why do none of the major (R)DBMS vendors provide native declarative DDL like MD3? I have no idea. They really should. If you look at tools like Microsoft's Visual Studio database projects you can see that there is an attempt to make things more "tell, don't ask", but it is half-baked at best. In VS database projects you declare the index using standard CREATE INDEX DDL, like this, which I pulled directly from one of my VS database projects:

This is certainly much easier than having to write an IF EXISTS statement, but it could be better. The way VS database projects work is that if you need to ALTER an index you simply change the CREATE INDEX command in the index script. So, to add an INCLUDE clause to this index is simply a matter of adding that clause to the above command. When the deployment runs it will run the necessary commands to get you what you requested, whether that is a DROP followed by CREATE, a CREATE WITH DROP_EXISTING, or whatever. But again, if you need to make bulk changes to all indexes, such as adding a FILLFACTOR or COMPRESSION you can't. That's why I feel it is half-baked.
Hopefully one day we'll have full declarative DDL in our RDBMSs. Even the big NoSQL implementations don't handle DDL any better. If you want to manipulate an index in Hadoop/Hive you still need to use CREATE/ALTER/DROP syntax. No improvement there. Mongo is a bit better. You don't use DDL at all, instead you call a .ensureIndex() method that will ensure your index "looks" a specific way before it allows your job to run. There are problems with this from an operational standpoint...such as the fact that this may cause your entire collection to serialize while the index is built...but syntactically this is a great improvement over standard SQL DDL and is getting very close to full declarative DDL.
The Single Responsibility Principle
 The SRP is a restatement of Unix's philosophy of Do One Thing and Do It Well. I've tried to make MD3 adhere to the SRP as much as possible. As I've shown already, unlike other deployment tools that make you use all of nothing of their solution, MD3 does not. I've had customers write their own deployer (covered soon in a post about
The SRP is a restatement of Unix's philosophy of Do One Thing and Do It Well. I've tried to make MD3 adhere to the SRP as much as possible. As I've shown already, unlike other deployment tools that make you use all of nothing of their solution, MD3 does not. I've had customers write their own deployer (covered soon in a post about RunMD3.ps1) to avoid using/learning Powershell. I've had others using VS database projects to deploy but use the MD3.Create procedures to manage their stateful objects. And every client loves the [[MD3 Model Data Patterns]] scripts.
Most deployment tools, such as RunMD3.ps1 and VS database projects, are single-threaded...meaning they are designed to run only one script at a time, serially. I had a client that was EXTREMELY sensitive to downtime and wanted to multi-thread their deployments, yet not have to deal with object dependency issues. Since MD3 is architected as independent services we were able to make the deployment multi-threaded very quickly simply by running the single-threaded RunMD3.ps1 concurrently with itself. We made the deployment code "multi-threaded" in two days and cut their deployments times by a factor of 4.
YAGNI
"You ain't gonna need it" is a principle of eXtreme programming that states that you should never add a feature unless it is needed. I totally agree with  this. For instance, I only added the ability to use index partitioning with MD3 in 2012 after I finally found a use case where partitioning would be the best solution to a problem. Prior to that I always solved my problems using other solutions that were at least equal to the task.
this. For instance, I only added the ability to use index partitioning with MD3 in 2012 after I finally found a use case where partitioning would be the best solution to a problem. Prior to that I always solved my problems using other solutions that were at least equal to the task.
I've had co-workers and clients complain that MD3.CreateIndex does not support critical features they think they need. An oft-cited example is filtered indexes. My retort is quite simple...I've yet to see a use case where filtered indexes are the best solution. I'm not saying filtered indexes are useless, I'm merely saying I, professionally, have yet to need them. Perhaps I'm just lucky and have never worked on a system that truly needed filtered indexes. Rest assured that the first time I need a filtered index I'll refactor MD3.CreateIndex so it properly supports this feature. So, if there are features you need either implement them yourself or contact me.
Separate Interface from Implementation
Some folks call this ISP (Interface Separation Principle). I prefer to call it "separating the interface from the implementation" because it seems to make more sense to people. The "Interface" is how you interact with your object, the "implementation" is what your object does under-the-covers. You should always try to isolate your implementation details from your users. As we've seen time and again, standard DDL mixing the "interface" (what you want to do) with the "implementation" (how you do it). When you use the MD3 procedures you are not exposed to the implementation details. You don't need to worry about what to do if you need to CREATE your object vs ALTER it, nor do you need to worry about dependent objects. Everything is handled for you. Yet since MD3 is implemented in TSQL you have the ability to see how the implementation is handled by MD3 and of course you can change that if it doesn't suit your requirements. The implementation details are hidden, until you need them.
Convention over Configuration
This is sometimes known as "coding by convention". CoC strives to keep the number of configuration options a developer/admin has to worry about to a minimum  and supply sensible defaults instead. Certainly having lots of configuration options is cool, but have you ever had a situation where you've changed a bunch of configurations only to find out that your software doesn't work and can't figure out which buttons and knobs you changed that are affecting the behavior?
and supply sensible defaults instead. Certainly having lots of configuration options is cool, but have you ever had a situation where you've changed a bunch of configurations only to find out that your software doesn't work and can't figure out which buttons and knobs you changed that are affecting the behavior?
MD3 has NO configuration file. None. Configuration isn't needed. When you look at your folder hierarchy you should be able to tell the order that scripts will deploy in based on their naming convention. All folders and scripts execute alphanumerically. This is covered further in my post on the MD3 executor, coming up soon.
I've had clients add various knobs and settings to customize MD3 for their specific needs and what they thought was a better implementation. That's fine. But the goal of good software is to not have to worry about configuring the software to have it do what you need.
So how do you configure MD3 without an XML, ini, or settings table? You use the MD3 patterns and conventions I've already talked about in these posts and will talk about in future posts. We don't need a configuration option that allows you to execute .sql and .sqlx files (whatever that might be). We use the most common option that everyone is familiar with...the convention of using .sql file extensions to indicate this is a SQL file. Of course you can change this if you need to, that's totally up to you.
Write Shy Code
This is sometimes called the Law of Demeter. I hate that name because it is an unnecessarily wordy, confusing, and obtuse way to explain a simple  concept. Do you even know who Demeter was or what she is famous for? Probably not. The LoD can be summed up by stating that your objects should be "loosely coupled". In other words, modules should not reveal anything unnecessary to other modules that don't rely on other modules' implementations. An example...if you need to change an object's state, get the object to do it for you. This way your code remains isolated from the other code's implementation and increases the chances that you'll remain orthogonal. Orthogonal is a fancy way of saying your code will "stay at right angles to other code"...which is another wordy way of saying you won't introduce "side-effects" if you change something.
concept. Do you even know who Demeter was or what she is famous for? Probably not. The LoD can be summed up by stating that your objects should be "loosely coupled". In other words, modules should not reveal anything unnecessary to other modules that don't rely on other modules' implementations. An example...if you need to change an object's state, get the object to do it for you. This way your code remains isolated from the other code's implementation and increases the chances that you'll remain orthogonal. Orthogonal is a fancy way of saying your code will "stay at right angles to other code"...which is another wordy way of saying you won't introduce "side-effects" if you change something.
We accomplish this in MD3 quite simply...all code has an interface in the form of MD3.Create procedures. These procedures take a given set of "properties" as arguments and nothing else. All state changes are hidden behind those interfaces. If those interfaces change, such as if we decide to add a new "property" to an object (perhaps adding @FilterClause to MD3.CreateIndex) we can rest assured that we do not have to worry about that code having unintended side-effects that may break other modules. And we can always test this with our CI build loops ([[Continuous Integration Testing with MD3]]).
You have just read "[[The OO Design Principles of MD3]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
sql server data architecture md3