
MD3 Script Idempotency and MD3.CreateColumn
| Quick Links |
|---|
| [[Introduction to Metadata Driven Database Deployments]] |
| Download MD3 (with samples) |
| Documentation on CodePlex/git |
| Presentation on MD3 |
| Other Posts about MD3 |
| AdventureWorks2013 reverse-engineered into MD3 (takes 5 mins to do with ANY database) |
In the last few posts of my MD3 blog series I've focused on how MD3 handles "stateful" database object deployments. Today I'm going to cover the most important stateful object in your database...the table. You really want to make sure you get your table scripts correct otherwise you risk data los. Basic CREATE TABLE DDL is already really simple to understand so MD3 doesn't get in your way with some cumbersome new syntax that you need to learn. However, MD3 adds some scaffolding code around the DDL to help you make your deployments bullet proof. Here's an example:
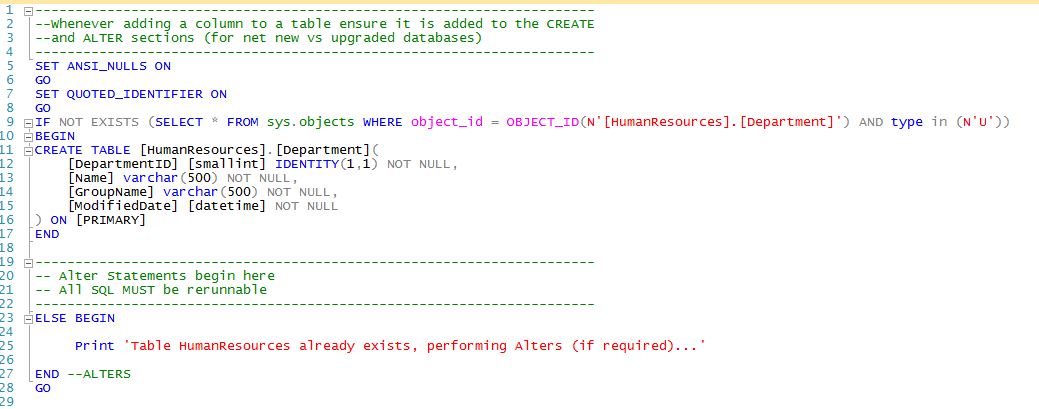
MD3 includes a script generator that will put your existing tables into the above format automatically and will be covered in [[How to Reverse-Engineer Your Database with MD3]]. But the script generator will not handle the "Alter" section of the script since this is the stateful history that you must provide. Sorry, but there's no way around that...no tool will provide this for you.
First, All MD3 scripts must be idempotent
An idempotent operation is one that can be applied multiple times without changing the result beyone the initial application. In SQL this is an operation that can be "rerun" without having any unintended side affects. For instance, this piece of SQL is NOT idempotent:
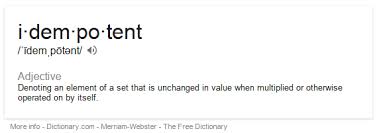 UPDATE dbo.Employees SET Salary = Salary * 1.10
UPDATE dbo.Employees SET Salary = Salary * 1.10
Every time you run this code it will give an additional 10% raise to every employee.
Every MD3 script must be idempotent, or "rerunnable", without "side-effects". This is because MD3 runs ALL scripts during each deployment. Some folks struggle with this concept. Two suggestions: ensure that you create proper CI testing (see [[Continuous Integration Testing with MD3]]) and whenever you write a script simply press F5 twice, then see if the results are what you expected. Some of my clients call this the "F5 F5 test". After a few weeks you'll be writing rerunnable scripts without even realizing it.
MD3.CreateColumn
...will help you add or alter a column based on the properties you provide. Here are the parameters:
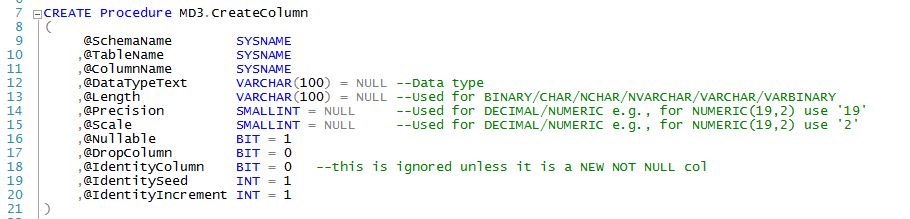
There are some benefits to using MD3.CreateColumn vs using standard DDL:
- removes constraints (unique, foreign key, check, and PK) if the column change requires those objects to be dropped
- removes indexes from the col, if needed
- less esoteric DDL to remember
When you drop a column with @DropColumn (instead of using ALTER TABLE...DROP) MD3 will automatically remove the dependent objects and will provide the developer with a message like this to remind them to remove those objects from source control.

Back to our Example
All MD3 scripts must be rerunnable. Note that the table script pattern above isn't required with MD3, but I've found this is the best pattern to use. In this 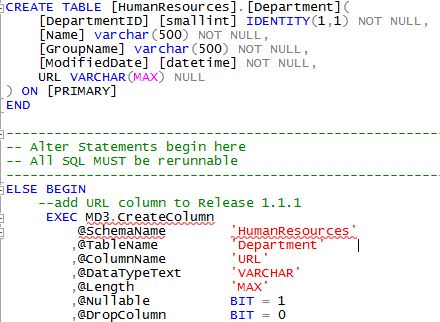 case the script is rerunnable because the table will only be created on the first execution of the script. On subsequent executions only the
case the script is rerunnable because the table will only be created on the first execution of the script. On subsequent executions only the PRINT statement will be output.
Let's assume that you have a new requirement to add a URL column to this table. Using the above pattern this is how I would do it. Note that we add the URL code to two places...the CREATE TABLE statement (covers a "net new" database) and as a call to MD3.CreateColumn (covers upgraded databases. On the second and subsequent executions of this script nothing will happen since the URL column has already been created as declared.
Interspersing DDL with data migration code
Some shops absolutely insist on separating DDL from data migration code. This is wrong. In many cases you must run data migration code either before or after your DDL runs. In these situations the data migration code is tightly coupled with the DDL and should be stored together. This aids in documentation and understanding for future developers.
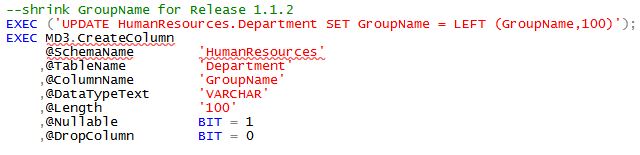 Let's look at a simple, contrived example. For some reason you have a requirement to shrink the
Let's look at a simple, contrived example. For some reason you have a requirement to shrink the GroupName column from varchar(500) to varchar(100). Further for existing data the requirement is simply to retain the first 100 characters. Here's how you would accomplish that using my MD3 patterns. First, you would change the definition in the CREATE TABLE statement (omitted from screenshot). Then you would run the UPDATE statement to retain existing data, then you would make the call to MD3.CreateColumn changing the parameter for @Length. As a side note, the UPDATE statement must be placed in dynamic sql otherwise the script will not compile on net new databases because the table does not actually exist. This is goofiness with TSQL, not with MD3. You can of course add any additional code you may want here. A backup of the table (or at least the GroupName column) would be a wise idea, just in case.
Add a non-nullable column to a table
This is another common use case that I see. This is a three step process:
- Add a nullable column to the table
- UPDATE the column to the default value for existing data per your requirements.
- Set the column to NOT NULL.
Here's how we do it with MD3. If you are sensitive to downtime and this is a large table we can do most of this work while the system is online, if we prepare properly and write the code to accomodate this.
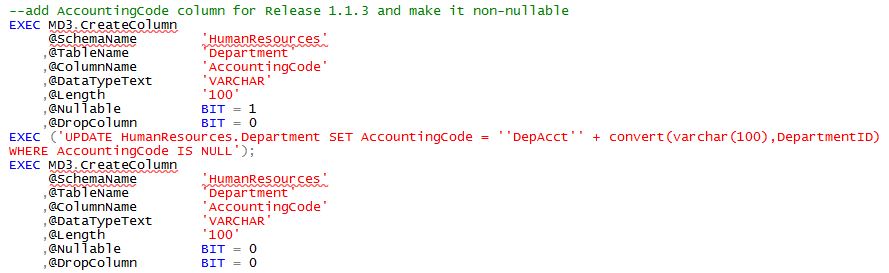
Here we've added an AccountingCode column and populated existing data with a "default" code, then set the column to NOT NULL.
Summary
All MD3 scripts must be rerunnable. This is, frankly, a good habit to get into. You never know who'll accidentally rerun your script without you knowing so scripts you write should never have "side-effects". We then looked at the pattern to use for MD3 table scripts. You don't have to use this pattern, but in my experience this pattern works best. There are scripts available with MD3 that will reverse-engineer your database tables into this pattern.
In the next post we'll take a break from the technical aspects of MD3 and look at [[The OO Design Principles of MD3]]. When you understand these principles you'll see how a tool like MD3 can solve a lot of problems that DDL can't.
You have just read "MD3 Script Idempotency and MD3.CreateColumn" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 sql server data architecture