
MD3.CreatePrimaryKey in Action
Metadata Driven Database Deployments (MD3) is my build-and-deploy mechanism for SQL Server-based applications. Check out the other posts in my MD3 blog series. In the last few posts we covered [[MD3 and "state"]] which showed how MD3 deploys "stateful database objects" using [[MD3 and The Four Rules|The Four Rules]]. In that post we covered how
MD3 blog series. In the last few posts we covered [[MD3 and "state"]] which showed how MD3 deploys "stateful database objects" using [[MD3 and The Four Rules|The Four Rules]]. In that post we covered how MD3.CreateIndex handles stateful index deployments. In The Other MD3.CreateProcedures we covered the other stateful object deployment procedures briefly. In this post I want to cover some use cases where MD3.CreatePrimaryKey can really help you evolve your database without having to code complex, error-prone DDL.
In the AdventureWorks sample database there is a table named HumanResources.Department. The PK is clustered and there is also one non-clustered index called AK_Department_Name.
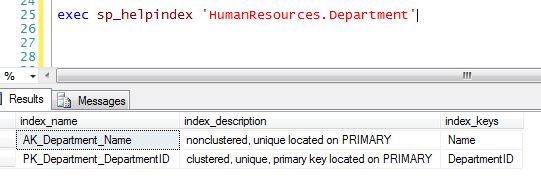
After doing some performance testing you determine that the table should really be clustered on Name and the PK should instead be non-clustered. That seems like an easy request so you start by trying to drop the existing clustered PK first.

But as you can see, that won't work because there is an FK that references that PK that would need to be dropped first. Dropping the FKs, in turn, will require you to recreate those FKs later, and any associated indexes, which is a lot of code to write, test, and deploy.
In MD3 this is much simpler. In MD3 and "state" I showed how there are really two ways to deploy stateful objects...by calling the MD3 procedures directly or by populating a metadata table with the desired properties.
Using the metadata table script
This is by far the easiest method. The metadata table that holds PK information is called MD3.PrimaryKeys. Here is what the (abbreviated) deployment script looks like for AdventureWorks' primary keys:
Let's a little hard to read so here is just the metadata entries specific for HumanResources.Department:

Since MD3 is declarative I only need to change the entry for the IsClustered property and I'm done. Here is the code I changed...the IsClustered property was changed from 1 to 0:

Now let's execute that script just like a standard deployment. Here is the output:

This is visible to the developer executing the script on her local development database, as well as the in the logs when this is finally deployed to your production databases. Since we are modifying a PK that requires the associated FKs to be dropped a message is logged to remind the developer that either the FK MD3 scripts will need to be rerun, or if running a full MD3 deployment this dependency is handled automatically and the FKs will be run. No custom DDL...very fast.
For a point of reference, here is FK MD3 script that the developer would run, or modify as necessary. And of course all of this can be run automatically using the MD3 deployer (RunMD3.ps1: The MD3 Executor).
And when you run the FK script you will see this output:
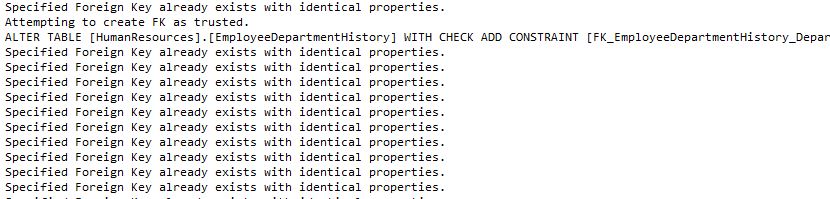
Note that all FKs already exist EXCEPT the FK that was automatically removed when we altered the PK. In the post The Other MD3.Create Procedures I mentioned that all FKs will try to first be applied as trusted, and you can see that this is in fact the case.
Using a direct call to MD3.CreatePrimaryKey
About half of my MD3 clients don't like keeping all of their PK properties in one metadata table (see the screenshots above). Instead, some like to create 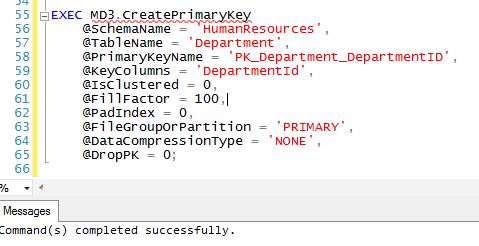 their stateful objects using calls to the MD3 procedures directly. They keep these calls in .sql files segregated by table name. There is a scripting utilitythat will script your existing stateful database objects into either the metadata format or direct MD3 calls ([[How to Reverse-Engineer Your Database with MD3]]).
their stateful objects using calls to the MD3 procedures directly. They keep these calls in .sql files segregated by table name. There is a scripting utilitythat will script your existing stateful database objects into either the metadata format or direct MD3 calls ([[How to Reverse-Engineer Your Database with MD3]]).
HumanResources.Department is currently configured with its PK as non-clustered. This is what the direct call would look like. Note that when I executed this I simply see "Command(s) completed successfully" because, according to MD3 and The Four Rules, the object already exists with the same name and properties, so it silently continues.
Let's say that after a while you determine that your decision to make DepartmentId a non-clustered PK was a bad idea and it really should in fact be a clustered index. What do we do? Write a bunch of hand-crafted, error-prone DDL? Nope, we simply change the @IsClustered flag. When a developer does this she sees these messages:
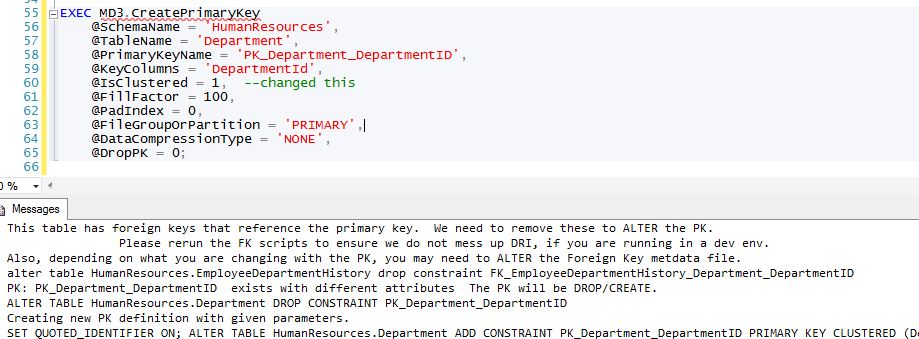
Note that the FKs were automatically dropped and a helpful message tells the developer to update the FK scripts if necessary. These are the same messages that will be seen during standard deployments as well.
Summary and Benefits of Using MD3
The goal of this post was to cover how the MD3 scripts in general, and MD3.CreatePrimary in particular, can spare you from writing a lot of complex, error- prone DDL. It is much faster to make these changes using MD3 and then have the proper CI testing in place ([[Continuous Integration Testing with MD3]]) to ensure all valid deployment paths are covered.
prone DDL. It is much faster to make these changes using MD3 and then have the proper CI testing in place ([[Continuous Integration Testing with MD3]]) to ensure all valid deployment paths are covered.
There are certainly lots of GUI-based tools that will also drop and recreate your dependent FKs whenever a PK changes. However, most of the implementation details are hidden from the developer and DBA. What if you need a custom deployment mechanism that those tools don't provide? MD3 can be customized...MD3.CreatePrimaryKey is just TSQL. In [[MD3 Extensibility Stories]] I'll give you a bunch of common use cases where MD3 can provide a quick solution where these tools cannot. Further, since MD3 is just a bunch of TSQL calls these scripts can be properly versioned so you can quickly see the evolution of your database from release to release. That's much harder to do with a GUI compare tool.
You have just read "MD3.CreatePrimaryKey in Action" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 sql server data architecture