
The CAP Theorem
Here is a little more of my experiences evaluating NoSQL solutions. It is important to understand the CAP Theorem. CAP is an acronym for Consistency, Availability, Partition Tolerance.
 In a distributed data architecture you can only have 2 of these 3 at any one time. You, as the data architect, need to choose which 2 are the most important to your solution. Based on your requirements you can then choose which NoSQL solution is best for you.
In a distributed data architecture you can only have 2 of these 3 at any one time. You, as the data architect, need to choose which 2 are the most important to your solution. Based on your requirements you can then choose which NoSQL solution is best for you. If a node goes down (called a network partition) will your data still be queryable (available) or will it be consistent (ie, queryable, but not exactly accurate)?
As a relational guy this makes sense to me. What distributed data guys have figured out is that the CAP Theorem can be bent by saying that you can actually have all 3, if you don't expect to have all 3 at any particular exact moment in time. With many NoSQL solutions the query language will have an option to allow a given request to honor availability over consistency or vice versa, depending on your requirements. So, if I must have query accuracy then my system will be unavailable during a network partition, but if I can sacrifice accuracy/consistency then I can tolerate a network partition.
It's usually not that simple unfortunately. It's generally not a wise idea, for hopefully obvious reasons, to write data to one and only one node in the distributed datastore. If we have, say, 64 nodes and every write only goes to one of those nodes, we have zero resiliency if a network partition occurs. That node's data is lost until the node comes back online (and you may even need to restore a backup).
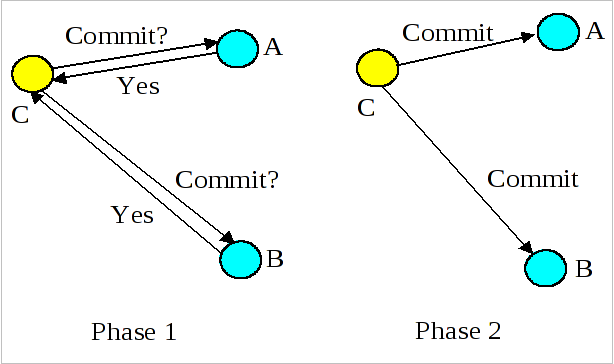 Instead, a distributed datastore will want each write to be acknowledged on more than one node before the client is notified of the write's success. How many nodes a write must occur on is an implementation detail. But clearly this means that writes will take a little longer in systems designed like this. It's equivalent to a two phase commit (2PC).
Instead, a distributed datastore will want each write to be acknowledged on more than one node before the client is notified of the write's success. How many nodes a write must occur on is an implementation detail. But clearly this means that writes will take a little longer in systems designed like this. It's equivalent to a two phase commit (2PC). This "multiple node write" issue also means that if we query for a specific scalar data element that any two nodes may have different values depending on which was updated last. This means that these datastores, while allowing queries to be leveraged against all nodes (map) and then merged to determine the correct version (reduce) will require a synchronization and versioning mechanism such as a vector clock. I'll discuss [[vector clocks]] and other synchronization mechanisms in the next post.
Other implementations may not require the "2PC" but will instead only write to one node but perform an asynchronous replication to other nodes in the background. They may use a messaging engine such as Service Broker or JMS to do this. Obviously, this is prone to consistency problems during a network partition. In this type of system the designer is clearly valuing performance of writes over consistency of data. Obviously a query may not return transactionally consistent data, always, in this type of system.
 The system designer has infinite latitude in how to bend the CAP Theorem rules based on requirements. Most of us RDBMS people don't like this kind of flexibility because we don't like when certain rules, like ACID, are broken. The interesting thing is, if you think about it, you can actually totally guarantee CAP in a distributed datastore if you remember that both readers and writers would need to execute against exactly half of the total nodes, plus one. This would assume a "quorum". Of course your performance on both reads and writes will be at their worst and will totally negate any reason for distributing data in the first place. IMHO.
The system designer has infinite latitude in how to bend the CAP Theorem rules based on requirements. Most of us RDBMS people don't like this kind of flexibility because we don't like when certain rules, like ACID, are broken. The interesting thing is, if you think about it, you can actually totally guarantee CAP in a distributed datastore if you remember that both readers and writers would need to execute against exactly half of the total nodes, plus one. This would assume a "quorum". Of course your performance on both reads and writes will be at their worst and will totally negate any reason for distributing data in the first place. IMHO. An area where a distributed datastore may take some liberties that freaks out us RDBMS folks is that a write may not *really* be a write. In the RDBMS world writes follow ACID. This means that a write can't be considered successful if I just write it to buffer memory. I have to write it to the REDO/transaction log and get a success from that. We've all been told in years past to "make sure your disk controller has battery backup so you don't lose your write cache in the event of failure".
Well, its possible that we can "bend" the write rules a little too. Perhaps we are willing to tolerate the "edge case" when we lose a write due to failure between the time the buffer was dirtied and when it was flushed to disk. So, some of these solutions will allow you to configure whether you need a "durable write" vs a plain 'ol "write". Again, the system designer needs to consciously make the tradeoff between durability and performance. This is a "setting" I've neither seen in an RDBMS nor even seen it requested as a feature. It's just a totally foreign concept. And in many cases the write/durable write setting can be changed at the request level, offering even more flexibility. In fact, it appears as though Microsoft is getting on board with this concept. It looks like [[Hekaton]] will support the concept of "delayed durability".
I see one last concern with these solutions, the cascading failure problem. If Node goes down then its requests will be routed to Node', which effectively doubles its load. That has the potential to bring Node' down, which will cause Node" to service thrice its load, etc etc. This can be overcome with more nifty algorithms, it's just worth noting that it's never wise to overtax your nodes. This is why NoSQL people always opt for more nodes on cheaper commodity hardware.
Dave Wentzel CONTENT
data architecture nosql