
RunMD3.ps1: The MD3 Executor
[[Introduction to Metadata Driven Database Deployments|Metadata Driven Database Deployments (MD3)]] is my build-and-deploy system for SQL Server  databases. In the last couple of posts of this blog series I covered what MD3 and why you should care about metadata-driven, declarative database deployments. In this post I'm going to cover how MD3, by default, executes its scripts.
databases. In the last couple of posts of this blog series I covered what MD3 and why you should care about metadata-driven, declarative database deployments. In this post I'm going to cover how MD3, by default, executes its scripts.
RunMD3.ps1
First, there is no requirement to use the script executor, called RunMD3.ps1. You can always use your own sql script deployment tool, such as Visual Studio db projects. Or you can write your own. I've written script deployment tools using batch files, osql, and vbscript. Do whatever works for you. For the remainder of this post I'll assume you are using RunMD3.ps1. Before we cover what this script does let's cover how we should deploy sql objects.
Database Deployment Best Practices
Here are some best practices for any database deployment tool:
- deploy ALL objects with EVERY deployment. This aids in CI Loops ([[Continuous Integration Testing with MD3]]) where we should compare upgraded databases to "net new" (shell) databases.
- Need to order the object deployments such that dependency errors are not thrown. For instance, we should apply tables before their indexes.
- A "status" should be available that tells the release engineer/DBA exactly what is currently being deployed. This helps if a given script, for some reason, decides to execute for longer than it should.
- Errors should be easy to recognize and should be logged. The errors should not be caught by the tool and obfuscated into the tool's error message. The actual SQL error message should be returned.
How MD3 handles these requirements
 You can of course customize this process to suit YOUR needs.
You can of course customize this process to suit YOUR needs.
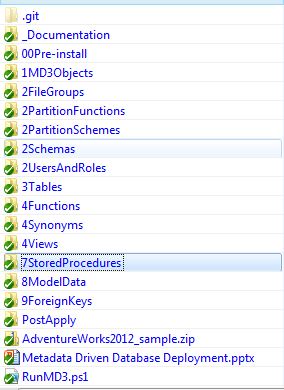
RunMD3.ps1only executes .sql files. This means you can intersperse unit test files (such as tsqlt scripts) or documentation files with your .sql files. Simply give them a different file extension.- Files and folders are run alphabetically. This means that you can simply look at your sql script folder structure and determine the order that scripts will execute. See the folder structure I use in the nearby graphic. Note that we deploy the MD3 system first (1MD3Objects) before we build any "user" objects like tables (3Tables).
- Sometimes (very rarely) you'll get dependency errors and this execution method won't work. For instance, you may have a view (4Views folder) called Bar (deployed in
4Views\Bar.sql) that calls another view called Foo (in4Views\Foo.sql). This will fail during your CI testing. No problem...two possible solutions:- rename
Bar.sqlto00Bar.sqland create a newBar.sqlwith a comment that states the file has moved due to an ordering dependency. - use subfolders
- rename
- Sometimes (very rarely) you'll get dependency errors and this execution method won't work. For instance, you may have a view (4Views folder) called Bar (deployed in
- Within a given folder, the .sql scripts are run PRIOR to any subfolders. For instance, in the
1MD3Objectsfolder you'll see the objects and subfolders in the nearby graphic.- In this case
CreateMD3Schema.sqlwill run BEFORE any .sql files that are in theFunctionsfolder. All MD3 objects are deployed to the MD3 schema, hence why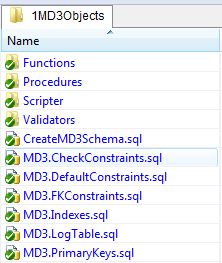
CreateMD3Schema.sqlis run first. Otherwise, you'll get a dependency error (mentioned above). - This convention allows you to structure your folders into "software modules" folders. For instance, you may have thousands of stored procedures under
7StoredProcedures. You may want to organize those into subfolders likeAccounting,HR,ETL, etc.
- In this case
- You can use whatever folder structure you like, and nest as deep as you like.
- If you wish to skip a folder from execution, preface the folder with "_". For instance, notice the
_Documentationin the screenshot above. That folder contains example .sql files. Those will NOT be executed. - If you wish to skip a file from execution either "zero out" (blank) the file or rename it to something other than .sql.
- Any valid TSQL will be executed. You don't need any special formatting or syntax.
If you use MD3's suggested folder hierarchy then ordering dependencies are minimized.
"Special" Folders and Files
These items break with the "convention over configuration" paradigm that I've designed with MD3 (discussed in [[The OO Design Principles of MD3]]).
PostApplyfolder: anything placed in this folder will run at the end of an MD3 deployment. This is useful for backup scripts, notification scripts, scripts to restart replication, SQLAgent jobs, etc..\00Pre-install\00CreateDatabase.sqlALWAYS runs FIRST. This script will CREATE DATABASE if needed. This is useful for CI Build Loops (discussed in the post [[Continuous Integration Testing with MD3|Continuous Integration Testing with MD3]]). You can also put backups scripts here or anything else that needs to run at the start of a deployment.
Errors, Logging, and Rerunnability
Since every script is (re-)run with each deployment you have to write your code to ensure it is idempotent/rerunnable. ([[MD3 Script Idempotency and MD3.CreateColumn|MD3 Script Idempotency]]). This is easy to test with proper [[Continuous Integration Testing with MD3|MD3 Continuous Integration Tests]].
When an ERROR occurs (Severity >= 11) in one of your scripts then MD3 aborts and displays and logs an error. Simply fix the error and redeploy. No need to restore the database first due to a failed deployment.
Back to RunMD3.ps1
Now that I've covered what RunMD3.ps1 does and why, let's cover how it does it. At its core it is a little Powershell script that recursively calls all folders and sql scripts starting in the root folder from where it is called. It is not written in something like Python or Perl which many database professionals may not understand. Other than this little script, MD3 is written entirely in TSQL. (I have an Oracle version as well, also entirely written in PL/SQL. Contact me for details).
It requires 2 parameters, the $ServerName and $DatabaseName of the database to be installed/upgraded. The source code is available here.

It uses NT authentication. It can be run remotely, but the machine executing RunMD3.ps1 must have the sql client installed. The entire script is about 200 lines of Powershell. The bulk of the code is:

Line 181 runs .\00Pre-install\00CreateDatabase.sql. This is discussed above. If you don't need this functionality simply remove this line of code. However, this code really helps with CI Testing by building your shell database. Line 186 calls each .sql script in every subfolder starting with the folder where RunMD3.ps1 lives.
That's it.
In the next post we'll take a look at [[MD3 deployments in action]].
You have just read "MD3.ps1: The MD3 Executor" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 sql server data architecture