
MD3 Deployments in Action
Over the last few posts we've covered how [[Introduction to Metadata Driven Database Deployments|MD3]] handles stateful database object deployments. We've covered all of the MD3.Create procedures and how they help you avoid writing error-prone, hand-crafted DDL. We then looked at RunMD3.ps1 which is the MD3 executor script. In this post we are going to look at various outputs you can expect from RunMD3.ps1.
deployments. We've covered all of the MD3.Create procedures and how they help you avoid writing error-prone, hand-crafted DDL. We then looked at RunMD3.ps1 which is the MD3 executor script. In this post we are going to look at various outputs you can expect from RunMD3.ps1.
Why should we build and deploy EVERY database script EVERY time, even if the object hasn't changed?
In MD3 Script Idempotency and MD3.CreateColumn we looked at why all sql scripts in MD3 must be "rerunnable", meaning that a script cannot have "side-effects" if it is subsequently executed multiple times. With MD3 every SQL script is run during every deployment. Folks that are new to MD3 question this approach.
| Quick Links |
|---|
| [[Introduction to Metadata Driven Database Deployments]] |
| Download MD3 (with samples) |
| Documentation on CodePlex/git |
| Presentation on MD3 |
| Other Posts about MD3 |
| AdventureWorks2013 reverse-engineered into MD3 (takes 5 mins to do with ANY database) |
Just suspend disbelief and you'll see the benefits of doing this.
- It’s the safest thing to do…you always deploy what you tested and what you expect. You never know who altered a stored proc on a database without going through the proper build/deploy mechanism. Simply redeploying all objects ensures that your database is exactly how you want it. Developers and QA folks can manipulate their environments and can later "reset" them by simply getting the latest code and deploying it.
- It only takes a few milliseconds to check metadata “properties” for an object and determine there is no net change. Even with thousands of database objects that haven't changed in years you will only spend at most a few minutes checking the metadata. Trust me. I've run MD3 scripts against HUGE databases where no objects have changed since the last deployment...this still only takes a few minutes.
- We are not locked into build-by-build deployments where we run only the scripts that we think have changed. We can upgrade any database to “current” without having to worry about the starting point. If you have customers who are behind by several releases you can rest assured that they will upgrade and have identical schemas to your newest customer.
- Frankly, this is how every other language does build/deploy. This is an industry standard best practice that encourages continuous integration. SQL should be no different. MD3 enables this.
Running RunMD3.ps1
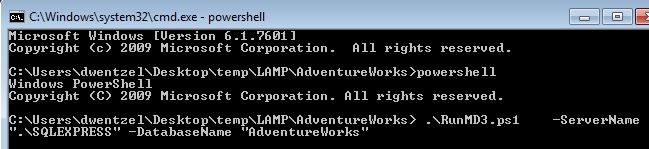
There are lots of ways to run PoSh scripts. I like to open a command prompt and start powershell. You then cd to the root directory where your MD3 deployment scripts reside. Then you simply call the deployment executor using PoSh dot notation, like this: .\RunMD3.ps1. There are two parameters -ServerName and -DatabaseName.
Prerequisites
- You can run the PoSh script from any machine with the sql tools installed. There are no special powershell requirements.
- If this is the first time you are running a PoSh script on the given machine then you must run
set-ExecutionPolicy Unrestrictedfirst. This allows you to run PoSh scripts. This isn't my requirement, rather a requirement of powershell itself. - The specified database must exist. This is the default behavior. You can of course issue the command to create your database first, if it doesn't exist, by placing the relevant SQL in
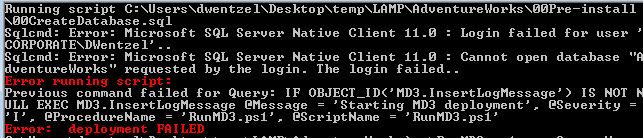
00Pre-install\00CreateDatabase.sql. In fact, this is a good idea if you are going to create CI Build loops (see [[Continuous Integration Testing with MD3]]). But by default, for safety reasons, MD3 requires the db to exist. If it doesn't you'll see an error similar to this:
Errors
Whenever an error is thrown with a Severity >= 16 the deployment will stop and an error message will be displayed. This works EXACTLY like SSMS.
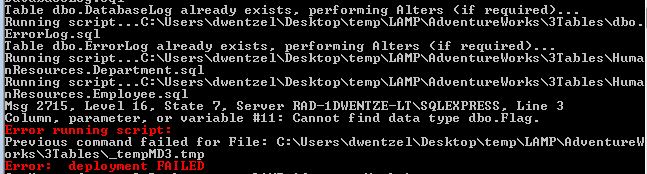
In this screenshot we can see that the failure occured in 3Tables\HumanResources.Employee.sql because the dbo.Flag user-defined data type does not exist. By using start-transcript, or by piping RunMD3.ps1 output, you can capture the execution log seen above to a text file as well. Execution logs are also saved to a table named MD3.Log. This table is truncated at the start of every deployment, so if you wish to archive the data from every deployment you must either alter the MD3 system or squirrel the table away to another location.

The following graphic shows the contents of MD3.Log after an error was thrown:

In this case we can see the error that was thrown. The constraint could not be created. The actual SQL statement that errored, that was generated by the MD3 system, based on the properties passed to MD3.CreatePrimaryKey (in the example), is always logged just before the error. This will help you determine what went wrong. These errors are extremely rare and should always be caught during continuous integration testing.
Here is what you can expect to see when MD3 succeeds:

Warnings
Any WARNINGs will be displayed just before the success message, or can be queried from MD3.Log by looking at WHERE Severity = 'W'. Out-of-the-box the only WARNINGs MD3 will throw are untrusted constraint violations (if you allow them). You can code your own by tactically adding calls to MD3.InsertLogMessage with the @Severity = 'W' option.
Summary
In this post we showed how to run the MD3 executor PoSh script, RunMD3.ps1. This utility executes any .sql file it finds in its folder or any subfolder. If a .sql script throws any errors those are bubbled up and logged to MD3.Log and are shown to the user running the PoSh script. In the next post we'll look at [[How to Reverse-Engineer Your Database with MD3]].
You have just read "[[MD3 Deployments in Action]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 data architecture sql server