
Querying NoSQL with Hive and Pig
This is my next post in my evaluation of NoSQL solutions. I want to cover Hive and Pig today, which are popular querying tools. First, it is important to understand that with NoSQL solutions you need to have specific, predefined ways of analyzing and accessing your data. Ad hoc querying and "advanced" query expressions that you would find in SQL (UNION, INTERSECT, etc) are generally not a very high priority in the big data world and are not implemented very well in the current solutions. We'll get there some day but for now the space is evolving so quickly and the maturity just isn't there yet. Heck, even SQL Server only began supporting INTERSECT as of 2005. The current query tools, although lacking at the "advanced" features are very good at what they are designed to do, which is manage large data sets.
 ...is built on Hadoop... ...is built on Hadoop... ...is built on Hadoop......get it? And Pig rides on top of Hadoop too.. ...is built on Hadoop......get it? And Pig rides on top of Hadoop too.. |
During my evaluation I spent most of my time working with Hive because I found the ramp-up time and tooling much better than Pig. Hive is very SQL-like and rides on top of Hadoop and is therefore geared to abstracting away the complexities of querying large, distributed data sets. Under the covers Hive uses HDFS/Hadoop/MapReduce, but again, abstracting away the technical implementation of data retrieval, just like SQL does.
But, if you remember from my "[[MapReduce for the RDBMS Guy]]" post, MapReduce works as a job scheduling system, coordinating activities across the data nodes. This has a substantial affect on query response times. Therefore, Hive is not really meant for real-time ad hoc querying. There's lots of latency. Lots. Even small queries on dev-sized systems can be ORDERS of magnitude slower than a similar query on a RDBMS (but you really shouldn't compare the two this way).
To further exacerbate the perceived performance problem, there is no query caching in Hive. Repeat queries are re-submitted to MapReduce.
So, if the performance is so bad, why does everyone expound on the virtues of these solutions? As data sets get bigger, the overhead of Hive is dwarfed by the scale-out efficiencies of Hadoop. Think of this as the equivalent of table scans in SQL Server. Generally we all hate table scans and instead try to find a way to do index seeks. But eventually we all hit a query tuning moment when we realize that a table scan, sometimes, is really better than billions of seeks. Remember that Hive is optimize for BigData and batch processing, so touching every row is optimal.
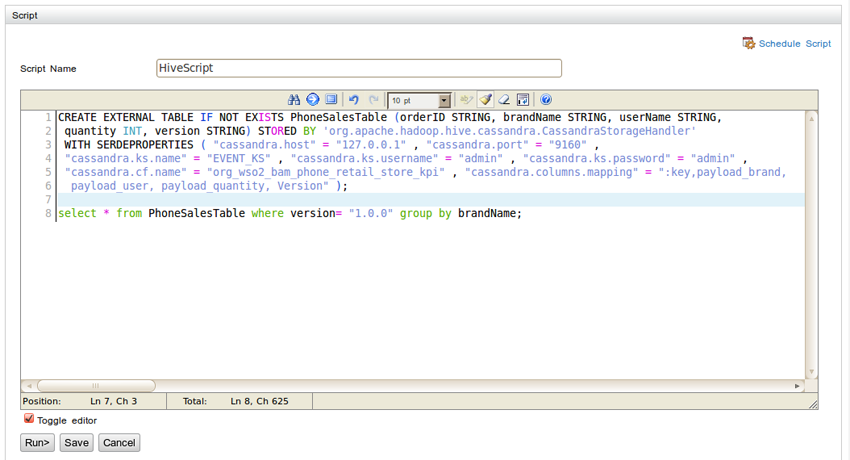
HiveQL
The HiveQL syntax is exactly like ANSI SQL. Here's an example:
Dave Wentzel CONTENT
data architecture nosql