
How to Reverse-Engineer Your Database with MD3
Metadata Driven Database Deployments (MD3) is my build-and-deploy system for SQL Server databases. In the last couple of posts we covered what problems MD3 solves and how it solves them. In this post in my MD3 blog series I'm going to cover how to reverse-engineer your database using MD3's  native capabilities.
native capabilities.
One of the biggest hurdles when migrating to a new build/deploy system, VCS, or data development tool is migrating all of your existing data and code into the new system. This is actually very simple to do in MD3. But first remember that MD3 is modular...if you don't want to use the MD3.Create* procedures then you don't need to run the migration scripts for those objects. You only need to reverse-engineer those objects that you want to use with MD3. The full reverse-engineering documentation is 32 lines of instructions...that's how easy MD3 is to get up and running. Here's the process:
- Find a pristine copy of your database to reverse-engineer. If you work in a shop with one production database then this is simple...script that database. But if you are an ISV (which MD3 is geared towards) then finding a pristine copy of a database to reverse-engineer can be difficult. Especially if your database was not properly versioned in the past. I can help you with this process if you contact me.
 Deploy the MD3 objects into a copy of that database. Basically just run
Deploy the MD3 objects into a copy of that database. Basically just run MD3.ps1with a clean copy of MD3. This will deploy everything you need and will not introduce any risk into your existing database.- Run the
MD3.Repopulate*procedures for each object type you want to migrate into MD3. - Run the
MD3.Script*procedures which actually generate the .sql files with the MD3 calls using simple PRINT statements. - Check your code into source control and begin working on your CI Loops.
- If something isn't working correctly you can simply re-script those items as many times as you need to, or you can manually update the metadata yourself.
It's that simple.
Let's look at what the Repopulate and Script procedures are doing under-the-covers.
Deep Dive - MD3.Repopulate Procedures
As mentioned in other posts in this series, stateful object properties are stored in tables that look very much like the underlying catalog views where SQL Server maintains its own running metadata (for instance, sys.indexes). The MD3.Repopulate procedures rebuild MD3's version of these metadata tables. Here's the code that handles index repopulation:
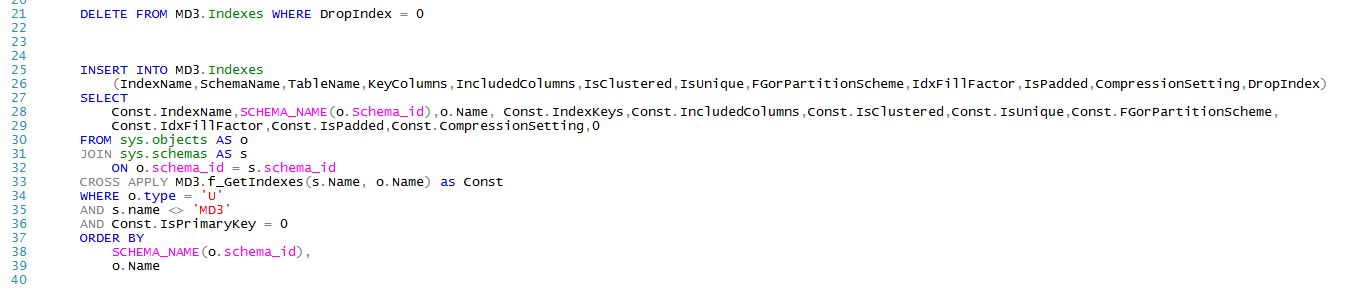
The bulk of the code starts on Line 25 and merely repopulates MD3.Indexes with metadata from your database. Notice how succinct the code is...database deployments are simple when you think through the actual requirements and understand The Four Rules.
 Line 21 might be confusing...we blow away what was last scripted...except cases where DropIndex was set. Why do we do maintain DropIndex data? Remember that indexes are stateful data and we must maintain their history. MD3 will script our current database, but it knows nothing about the history that existed in prior versions of your database. So, for instance, perhaps you had some old indexes in previous releases that you determined served no real purpose (ie, all activity was writes with no reads) and you dropped them. Now you script your current database into MD3 but you want to use MD3 to drop those old indexes from older customer databases. By manually adding the DropIndex metadata (just the index name) you can be sure that any databases that still have those indexes will have them properly dropped.
Line 21 might be confusing...we blow away what was last scripted...except cases where DropIndex was set. Why do we do maintain DropIndex data? Remember that indexes are stateful data and we must maintain their history. MD3 will script our current database, but it knows nothing about the history that existed in prior versions of your database. So, for instance, perhaps you had some old indexes in previous releases that you determined served no real purpose (ie, all activity was writes with no reads) and you dropped them. Now you script your current database into MD3 but you want to use MD3 to drop those old indexes from older customer databases. By manually adding the DropIndex metadata (just the index name) you can be sure that any databases that still have those indexes will have them properly dropped.
Essentially you are telling MD3 what the history of your database really was. No database reverse-engineering tool on the market can handle recreating history for dropped objects, and neither can MD3. You must supply this history, if you need it.
By using this method you can re-script your database numerous times while you test your MD3 migration with CI Build Loops without interrupting your current developers who are still actively using your previous deployment method.
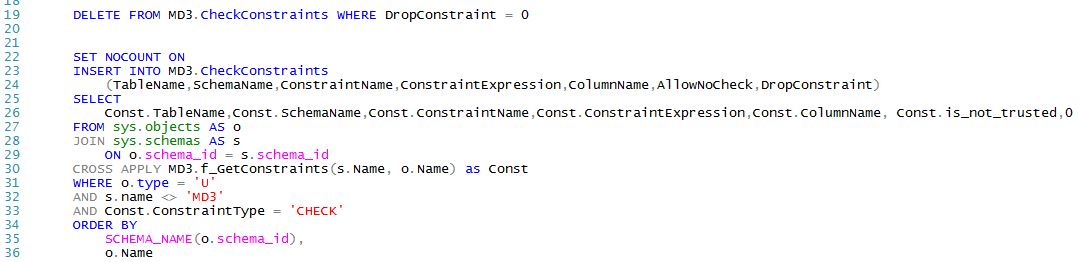
All of the MD3.Repopulate procedures work similarly to MD3.RepopulateIndexes. Here is an example demonstrating how CHECK CONSTRAINT repopulation works:
Deep Dive - MD3.Script Procedures
Once you have the metadata scripted to the MD3 metadata tables you need a method to get that metadata into .sql files so you can properly place it under source control. To do this we have stored procedures that use PRINT statements to "generate SQL from SQL". You simply save the output to your indexes folder. The output is a MD3-formatted script that follows the [[MD3 Model Data Patterns|ModelData Pattern]] discussed earlier. The output will look something like this (this is from Adventureworks):

The screenshot shows the last index in AdventureWorks that was scripted (Line 110). Note that after we populate MD3.Indexes with simple INSERT statements during a deployment we immediately apply the indexes on Line 113 by calling MD3.RunIndexes, which does all of the heavy lifting. Very simple.
Putting It All Together...Reverse-Engineering AdventureWorks
I have included a copy of the reverse-engineered AdventureWorks2012 SQL scripts in MD3 format with the source code (click here for the code). The scripts include all necessary code to reproduce a "net new" (shell database without the data) copy of AdventureWorks2012. And this only takes about 10 minutes to reverse-engineer on your own.
You have just read "[[How to Reverse-Engineer Your Database with MD3]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
sql server data architecture md3