
Convention over Configuration
"Convention over configuration" (CoC) is one of the newer catch phrases you'll hear as a architect. I really don't know where this started but when I learned Ruby on Rails this started to make a lot of sense to me. Also known as "coding by convention" this is a design paradigm that seeks to limit the  number of decisions that developers need to make, keeping things simple. When something needs to be unconventional you simply "manage by exception" and specify that which is unconventional. In other words, lengthy web.config files are no longer needed unless something is unconventional. This leads to less code, more simplicity, less bugs, less documentation, etc. In this post I'll cover some areas for CoC improvement in SQL including one of my ideas that I've never seen proposed anywhere else that would eliminate TONS of bugs in SQL, not to mention cut down on needles SQL verbosity.
number of decisions that developers need to make, keeping things simple. When something needs to be unconventional you simply "manage by exception" and specify that which is unconventional. In other words, lengthy web.config files are no longer needed unless something is unconventional. This leads to less code, more simplicity, less bugs, less documentation, etc. In this post I'll cover some areas for CoC improvement in SQL including one of my ideas that I've never seen proposed anywhere else that would eliminate TONS of bugs in SQL, not to mention cut down on needles SQL verbosity.
We need more of this in SQL Server, RDBMS, and data technologies in general. That's the gist of this post.
An Example of CoC
Your programming language du jour probably has classes and some of those will loosely map to your database tables. Instead of a class being named "classEmployee" and the table being "dbo.Employee" we have a convention that "the class name is the table name"...unless of course it is specified as unconventional. So the class would be Employee as would the underlying table. Now there is no need to map this relationship explicitly. Best practices suddenly become implicitly enforceable.
The Need for CoC in SQL Server...Cursors
TSQL and SQL can be very verbose languages. For the most part, these languages are declarative and not procedural. If you can eliminate declaring some things by using sensible defaults, then you are improving the language. IMHO. Let's look at a simple example of where CoC could help us be less verbose...cursors. After that I'll show you my biggest pet peeve with the SQL language and how I propose solving it using a CoC approach.
How do you write cursors? I bet it's a tedious and error-prone process. If you say that you NEVER use cursors and NEVER found a good use for them then stop reading, you are apparently a genius and I am not worthy of your time. For the rest of us that know that cursors are sometimes the ONLY way to do something in tsql, read on.
Here is a screenshot of a very hacky cursor. It merely prints out a list of database objects and their type. This is probably the simplest cursor you could create in SQL Server. You'll notice a bit of verbosity. For instance, the FETCH NEXT statement in repeated in the code. No big deal, but we
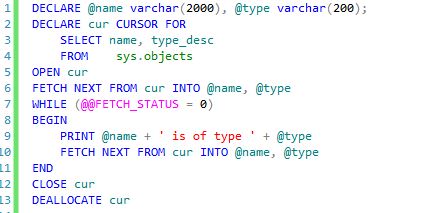
shouldn't have repeated code. I'll bet you that at some point in your career you wrote a cursor and, in haste, forgot that second FETCH NEXT statement and put your code into an infinite loop.
Ugh.
You'll also notice on Line 1 that I was too lazy to see what the actual datatypes were for the cols in question so I just set them to varchar(2000) and varchar(200), which should be big enough. Right? I'll bet you've done the same thing in haste at some point in your career too.
Cursors are just too darn tedious. They follow a pattern (or you can use one of the templates in SSMS) but even so, it is still tedious, and therefore error-prone.
One way we could eliminate the datatyping tedium, as well as remove the entire declaration of "cursor fetch variables" is if Microsoft gave us a shortcut
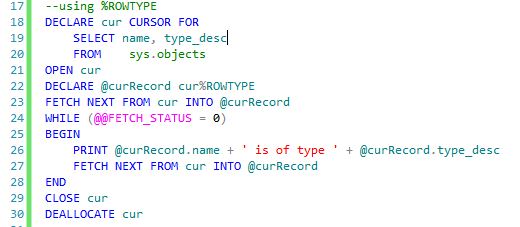
similar to Oracle's %ROWTYPE. In Oracle if you add %ROWTYPE to a variable the variable will assume the datatype of the underlying referenced object. It does this by declaring a "record variable" over the input. A bit of TSQL pseudo-code might help to illustrate this.
First, you'll notice we no longer have to declare the individual variables for every column referenced in the cursor. Our example only has 2 columns, but I'm sure you've written cursors with 10 cols being referenced, first in the "declare" section, then at least twice in the FETCH statements. That's a lot of repeated code to screw up.
Instead we declare a record type against the cursor on Line 22 and tell the record type that it should inherit the underlying columns and datatypes. We can now reference the variable using dot notation on Line 26. Using something like %ROWTYPE saves a lot of typing and it makes things a lot easier to read. But it's still too wordy.
What would be REALLY nice is something like this.
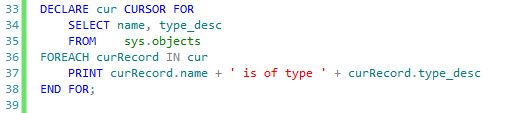
Look at how nice and compact this is. Further, it follows the FOR EACH...LOOP looping construct that every major language has these days. Here I don't even need %ROWTYPE because I get the record object right from the cursor (cur) object. No FETCH NEXT statements, no CLOSE/DEALLOCATE statements, no individual variable declarations for each column.
Yes I know that this syntax severely limits your ability to use advanced cursor techniques. This syntax is entirely forward only fetching only the NEXT row. I'm cool with that. I'll bet 99% of cursors you've written have been forward only, fetch-one-at-a-time cursors anyway. And when you need that other functionality you can always fall back to the old TSQL cursor syntax.
That's in the spirit of Convention Over Configuration...or "managing by exception".
My Contribution to CoC - the KEY JOIN (quasi-NATURAL JOIN)
Here is my (I think) original contribution to CoC in SQL Server. I've never seen this proposed...if it has been then I'm sorry and did not mean to steal anyone's idea. It's called the KEY JOIN.
How many times have you seen a query with a structure like this

No big deal right? I want to see all employees with the data for the department that they are assigned to.
To me that query seems very "wordy". Think about it, 99% of the time when you are JOINing employee to department it is going to be by DepartmentId. There is no reason why it would ever be anything else.
And, IMHO, in about 99% of EVERY JOIN I've EVER written I've always JOINd the tables by the same cols...and those cols are the PK on the parent side to the FK on the child side.
The 1% of the JOINs that aren't by key are really edge cases. Sometimes these are analytic queries and sometimes these are queries where I'm looking to find "fuzzy" matches so I don't want to use the key.
For the other 99%, I see an opportunity for CoC. We can manage the 1% as an exception.
NATURAL JOIN?
Well, it just so happens that the ANSI SQL standard has a NATURAL JOIN syntax that seeks to alleviate the ON clause, thus aiding readability. Here is the above query using the NATURAL JOIN syntax:

So much easier to read without that ON clause.
But few vendors (Oracle is one) support NATURAL JOIN. In fact, NATURAL JOIN is highly discouraged from use. Why?
- a
NATURAL JOINactually joins tables by like col names, not DRI. - it's generally thought that if a key col name changes then the
NATURAL JOINwould break everywhere so the ANSI standard protects us from our own devices. But seriously folks, if you rename a key col you better realize that you are going to have A LOT of code that changes. This is a ridiculous argument
To be clear, in the employee/department example if I used NATURAL JOIN the join would be by DepartmentId, assuming it is common in both tables. But if Name is common in both tables then the join would be but that col as well...and clearly dbo.employee.Name is something entirely different from dbo.department.Name. Also, many tables you work with probably have auditing cols that are always named the same CreUserId and CreDTime for instance. In the NATURAL JOIN world those cols would also be part of the equi-JOIN, which is clearly not right.
So NATURAL JOIN, while far more succinct, is worthless in modern RDBMSs, which is why it is discouraged from use. Darn. This is also why most RDBMS vendors don't even bother to support it.
So, I would love to see something in the ANSI specification (or MS could just implement it as their own extension in TSQL) called something like KEY JOIN.
KEY JOIN's Conventions
- A
KEY JOINwill always join two objects by their DRI. This will be a PK or Unique Key on the parent side and a FOREIGN KEY on the child side. - If DRI is not present between two objects referenced in a
KEY JOIN, then an error should be thrown. - A
KEY JOINwill assume INNER (INNER KEY JOIN) unless otherwise specified. Just likeJOINis short forINNER JOIN,KEY JOINis short forINNER KEY JOIN. LEFT (OUTER) KEY JOINwould indicate an optional JOIN from tableA to tableB, following the same semantics as aLEFT OUTER JOIN.RIGHT KEY JOINandFULL KEY JOINwould work the same asRIGHT JOINandFULL JOIN, except the ON clause would be assumed.- If an ON clause is found during query parsing with a
KEY JOINthen an error should be thrown.
Can anyone see a downside to KEY JOIN? I can't. This would really solve readability and errors due to accidentally picking the wrong join condition. Here is a query I wrote that attempts to show all column names for all tables. But it's not working. Why?
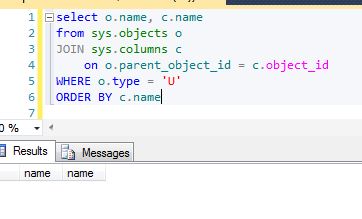
Yeah, the ON clause is wrong. That was probably easy to spot check, but as your queries grow larger your odds of JOINing incorrectly increase and 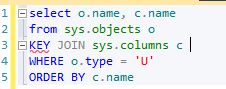 the ability to spot the bug becomes more difficult. With a
the ability to spot the bug becomes more difficult. With a KEY JOIN it is almost impossible to screw the query up. That's just much easier to read.
I have no clue why this isn't part of the ANSI standard.
Lastly...CREATE or REPLACE
Here's another pet peeve of mine with SQL Server...the verbosity of simple tasks like deploying a new version of a procedure in a database. I'm sure EVERY stored proc you've EVER written followed some pattern like this:

Maybe you construct Line 1 a little different, but I'm sure the basic pattern is the same.
Why oh why can't we just have this?
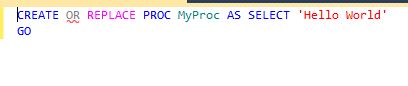
Oh well.
How can you spot an opportunity for CoC?
I like to write code using known patterns that I've used for years. Those patterns (like the cursor example) work 99% of the time and I don't need to ever think about the verbosity of the code I'm trying to write. I just use the pattern. In the past few years I've realized that patterns really aren't that good after all. A pattern is just needless verbosity and configuration that will lead to subtle errors. If we had a shorthand for the given pattern then we could make that the convention and merely manage by exception. You should look for patterns in your own work that you can factor out and set up as an implicit convention. This will save you a lot of bug grief and make your code easier to document.
I've proposed and up-voted many of the above items on Connect (such as %ROWTYPE) and Microsoft just doesn't care. As for KEY JOIN...well, one day I'm going to seriously propose that.
You have just read [[Convention over Configuration]] on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
data architecture