

Top 10 Data Governance Anti-Patterns for Analytics
At the Microsoft Technology Center (MTC) we talk to a lot of data leaders that are struggling to leverage their traditional data governance approaches in the Age of Advanced Analytics. Formerly tried-and-true governance approaches are not working anymore and they can’t exactly put their finger on the reasons. Analytics has changed and data governance has not kept pace. Microsoft and the MTC has some patterns and processes that can help you modernize your governance to achieve your Digital Transformation goals.
What is Data Governance?
There are entire books on data governance that you should refer to if you need a refresher. Data governance is the overall management of the availability, usability, integrity, and security of an enterprise’s data assets. Most companies will have a data governance body that sets the rules, defines the procedures, and ensures the various data teams execute on the plan.
The Big Problem with Data Governance
Data has changed radically the past few years and governance best practices have not kept up. Years ago we only had operational systems where the notions of governance were easy and not too controversial. For example: few users had the ability to query the data directly for fear of bringing the system down, therefore the default posture was to DENY access. When we built the first generation of analytical systems (namely, data warehouses) the governance was only slightly more complex. Users now wanted the ability to query the data themselves, which usually involved exporting the data to Excel because we still feared that the user might issue a rogue query and bring down the analytics system. Every company governed these access requests differently based on its culture … some trusted their users and allowed access, others did not.
Today, data sources have exploded and business users are demanding Self-Service Analytics. They want to be able to look at data on their terms and do Exploratory Data Analytics without the need for IT to broker access. Data lakes and lakehouses have exploded which further encourage users to be curious about their data assets. With a data lake the users merely wire up their own compute instance (which might be a data warehouse, Spark, Power BI, or Excel) to the data asset and they can do whatever they want. Dashboarding and visual query tools like Power BI are easy to use and more business users are comfortable writing a modicum of SQL, the lingua franca of data.
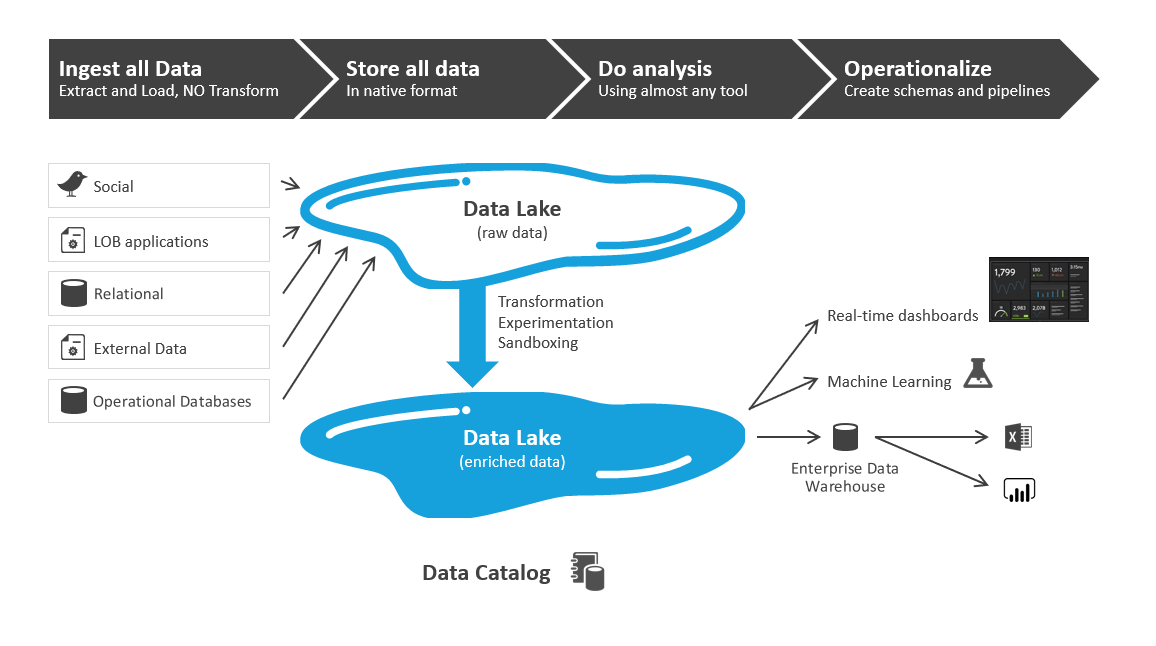
Data governance teams have not kept pace. They are not accustomed to granting access to data for experimentation. They want to know what the data will be used for. Their default posture is to limit access to data. Certainly it makes sense to limit business users from having direct query access to operational systems that likely contains PHI and PII, but why hinder a business user from valuable data that can be monetized?
Too many business people equate “data governance” with being told NO. If that’s your company, you need to start changing that culture NOW. Companies that CANNOT leverage their data assets to make data-driven decisions will soon find themselves marginalized as their competition embraces the promise of Digital Transformation. Data governance should enable innovation, not be its roadblock.
Data Governance Anti-Patterns
Here are some common Data Governance Anti-Patterns we see at the MTC, and our recommendations for solutions.
Anti-Pattern 01: Data governance as an IT function
Is your data governance team comprised solely (or even mostly) of IT personnel? If so, I’ll wager your data governance is not aligned with your business goals. A company’s data is not OWNED by IT, it is owned by the business. IT is merely the steward. Business units should have representation on all governance committees. Data governance is multi-disciplinary and should be an enabler of business value.
Data governance is not a function of IT. It should be driven by the business in support of company objectives.
Anti-Pattern 02: Relying on a Tools-based Governance Approach
 Too many times I hear “we want to use Azure Purview to help us with tagging, classification, access, and lineage of our data to help us with data governance project”. Azure Purview is great for that. The problem is you told me a TECHNOLOGY problem. When I probe deeper around what the company’s strategic goals are for its data assets I don’t get clear answers. And I never hear: “Well, we talked to our business users and what they would really like to see is…”.
Too many times I hear “we want to use Azure Purview to help us with tagging, classification, access, and lineage of our data to help us with data governance project”. Azure Purview is great for that. The problem is you told me a TECHNOLOGY problem. When I probe deeper around what the company’s strategic goals are for its data assets I don’t get clear answers. And I never hear: “Well, we talked to our business users and what they would really like to see is…”.
The data governance goals should drive the governance tool choices, the tool should not drive the governance goals.
Data governance is a journey, not a destination
Anti-Pattern 03: Putting PII/PHI/sensitive data in the lake (therefore necessitating governance)
Data lakes are the best and most-often used tools for analytics. But I see technologists copying EVERY piece of operational data to the lake. Why? I can see no good reason to put credit card numbers or SSNs in a data lake. They serve no analytical purpose. The more copies you make of sensitive data the more your risk for a breach increases.
I’ve heard data leaders say they need some sensitive data in the lake so the lake can be “the single source of truth” and support operational reporting that requires this data. If that’s the case then you have 2 choices:
- Make a copy of the sensitive data into the lake and risk a breach. Then you’ll need to determine how to mask the data and how to ensure every analytics tool is honoring the masking. This isn’t easy. It takes a lot of work and introduces too much risk, especially if a business goal is Self-Service Analytics, which implicitly means a more “open” approach to data.
- Don’t copy the sensitive data and find another way to support those reporting needs that require sensitive data. This is a much better approach.
- Use a data mesh approach where my reporting tool can call an API to retrieve sensitive data for reports that require it.
- Have a separate data structure with separate reports for sensitive data.

Anti-Pattern 04: Using the same governance rules for all lake zones and analytics datasets
Data lakes (or whatever you use for your analytics sandbox) have “zones”. Everyone calls the zones by different names – “landing”, “raw”, “curated”, “bronze”, “silver”, “gold”. There are 2 key reasons why we have zones. Based on the zone name we should implicitly know:
- … the quality of the data. “Gold” data should be highly certified, guaranteed-accurate data, whereas “raw” might be a bit dirty, duplicated, or, well, raw. Quality is one component of governance, therefore, we should expect that some zones will have dirty data. That’s ok.
- … who should be using it. Gold is likely meant for all self-service users. Therefore it should be modelled and governed accordingly. “Raw” should only be used by data scientists or those personas that understand that this data should not be used to derive quarterly sales data that we give to the SEC.
Different areas of the data lake should have different governance approaches.
Self-service analytics REQUIRES a more “open” approach to data access. There is no other way.
Anti-Pattern 05: Insisting on “Early” Governance
Sometimes when I help customers with a difficult analytics problem I’ll have someone interrupt me and want to discuss the data governance implications of the outputs of our work. Said differently, they want to control the data we are trying to produce BEFORE WE’VE EVEN PRODUCED IT.
This is the wrong approach.
The better approach is to allow the analytics team to find “the nuggets of gold” first, and solve the business problems. Then, as part of a review process, let’s have a thoughtful conversation about how we should govern our new insights.
- Is this regulated or sensitive data?
- Is this something that we want to provide to our self-service users? Should it be queryable in the gold zone? If so, should this data be on a dashboard? Is it discoverable in the data catalog?
- If it is in the catalog do we allow anyone to see the data or do we want to have users make a request so we can track why and how they are using the data? This will help us further understand the governance needs without making knee-jerk decisions at the start of a project before we understand the knowledge our users are creating.
I call this “late governance”. We are deferring all governance decisions until we are sure we have generated a valuable business insight. I’ll say it again, data governance should not stifle innovation.
“Early” data governance is diametrically opposed to self-service analytics, which is a business goal for every customer I talk to.
Similarly, most analytics projects I work on will require the team to ingest new datasets. Proponents of “early governance” will insist that this new data be controlled, before we’ve even experimented to see if it provides lift. This stifles the experimentation process.
Anti-Pattern 06: Following a “One-Size-Fits-All-Personas” Policy
 Some analytics personas will want access to the most raw, dirty data, so they can spot trends and anomalies. Think data scientists. They will want access to the “raw” or “bronze” area of the data lake. But this data would be overwhelming and misinterpreted by other personas (like business users). Let these other folks see that the data is available (via the catalog), but make them request access and explain why you are asking them to request access to it (because you want to understand why they want access to raw data). Other personas need “self-service” analytics but don’t really have SQL skills. These users should have access to summarized and “certified” data that they can use in Power BI or Excel. These personas would have access to the “gold” and “platinum” zones which would map closely to the semantic tier and data warehouse facts and dims. “Business analyst” personas that understand SQL might need access to more granular, yet “clean”, data. This maps closely to the “silver” or “curated” zones for most data lakes.
Some analytics personas will want access to the most raw, dirty data, so they can spot trends and anomalies. Think data scientists. They will want access to the “raw” or “bronze” area of the data lake. But this data would be overwhelming and misinterpreted by other personas (like business users). Let these other folks see that the data is available (via the catalog), but make them request access and explain why you are asking them to request access to it (because you want to understand why they want access to raw data). Other personas need “self-service” analytics but don’t really have SQL skills. These users should have access to summarized and “certified” data that they can use in Power BI or Excel. These personas would have access to the “gold” and “platinum” zones which would map closely to the semantic tier and data warehouse facts and dims. “Business analyst” personas that understand SQL might need access to more granular, yet “clean”, data. This maps closely to the “silver” or “curated” zones for most data lakes.
This structure allows far more flexibility. We can give everyone access to what we think they need based on their persona and they always have visibility into ALL data and can request access if needed.
Never force your data scientists to use data warehouse data (facts and dims). It almost never works for their needs. They’ll get frustrated and you will stifle their innovation. Data lakes were originally built to store data that these personas needed to do their jobs. Since then everyone else has seen the efficacy in using the lake for analytics where the data is easier to manipulate.
Anti-Pattern 07a: Denying write access to users
One of the goals of a data lake is to be “an analytics sandbox”. This means users will need to make copies of data for experimentation…they’ll need to semantically-enrich that data (usually via SQL) and they’ll need to save copies of it somewhere where they can reference it and continue to build upon it as they search for business value. To do that they need to have write access to the sandbox area of the lake. The sandbox is very much like a temp table in SQL Server.
Human users, whether business analysts or data engineers, should never have write access to any area of the lake except the sandbox. The remainder of the lake should only be writable by the scheduler/job user. Not even the Ops Team should be allowed to write to the lake. This is a core lake governance concept.
In the past the DBA never gave write access to the warehouse to common users. This made analytics very difficult since most analysts are not able to do all of the data enrichment they need in a single SQL statement. This is why it was always easier for a user to export the data to Excel and do the analytics there.
Anti-Pattern 07b: Allowing Shared Sandboxes
While we want users to be able to have a writable sandbox, we do NOT want them to have a shareable sandbox. Why?
Imagine your analyst, Annie, found a valuable business insight and has it persisted in her sandbox. She tells the Operations team she would like to move it to the data warehouse so it can eventually be added to a Power BI dashboard. The governance team finds out and wants to hold various meetings to understand the data better. The data warehouse team says they’ll need 3 months to integrate the data into the fact table. The dashboarding team wants to meet with Annie to understand…ugh…isn’t this exhausting? Annie found something valuable and she’s being punished. What does she do? She shares the data in her sandbox with her team…and likely later she shares it with everyone. Now the data is “published” in various Power BI dashboards and has zero governance. That’s not good.
Make people follow the governance process by not allowing ad hoc sharing. If users complain about stifled innovation then that means your governance process needs an overhaul. FIX IT!
You’ve probably heard the old aphorism: Without governance the data lake soon turns into a data swamp. Not true. If you follow all of the above advice there is NO WAY you’ll ever have a swamp. But make sure your processes aren’t so onerous that you are a drag on innovation.
How can you spot an organization that struggles with data governance? They have obviously inefficient business processes.
Anti-Pattern 08: Not Managing By Exception
Business users will find all kinds of valid reasons to do things that violate governance rules. It’s OK to make exceptions to your governance plan.
Here’s an example I’ve seen many times: the governance team mandates that only Spark, Synapse, and other “approved” tools can be used to query the data lake. But eventually a department will purchase a query tool they want to use with THEIR data. Too many organizations will disallow this. Why? This really doesn’t make any sense. The compute engine (ie, the “tool”) is not important, the data is.
With a data lake, the model should be “Bring Your Own Compute” (BYOC). Use the tool you want to use.
This is just one example. Governance teams need to be aware of when exceptions to policies need to be made.
In so many companies I work with the users equate “data governance team” with NO. Don’t let this be your company.
Anti-Pattern 09: Putting the Permissioning at the Compute Layer
Always do the ACL’ing in the data lake. This allows users to BYOC (see above). The tool no longer matters. The user simply logs in and the tool passes the credential to the lake to determine access.
Never apply the permissions at the compute tier, do all permissioning strictly at the data persistence tier…the lake.
Anti-Pattern 10: Mandating All Data Be in the Official Corporate Data Lake
This never works. Why? For the same reasons departmental data marts sprung up 20 years ago in spite of the corporate data warehouse: The business can’t wait for IT, so it builds its own solutions. We would call these “skunkworks” projects or “Shadow IT”. These projects would solve the immediate business problem, but at the long-term expense of data governance and building more and more data siloes.
Every customer I talk to has multiple data lakes (“ponds?”). Most are structured around business units. My advice is not to stifle this innovation simply to conform to a corporate governance standard. Instead, assist these business units with their governance efforts by providing the tools and templates you are using for the corporate lake. Help them, don’t hinder them.
Data governance is not a “project”. Data is constantly changing, and so is the data management field. Data governance should be viewed as an on-going corporate “program”.
How the MTC can help
Is your data governance team embracing modern analytics notions like:
- self-service analytics
- exploratory data analytics (EDA)
- data monetization (using your data assets to drive business goals in non-traditional ways)
- prescriptive analytics (using data to augment decision making that formerly was done using gut insights. Example: What should be our next marketing campaign?)
Data governance is a bigger problem today than ever. Companies are using data for more novel use cases and regulators are taking notice. But your governance strategy still has to foster innovation. Your company’s view of its data estate and risk tolerance has likely evolved in the last few years. Self-Service Analytics is impossible to achieve with outmoded governance anti-patterns that I’ve outlined above. This is a delicate balancing act that the MTC understands very well. If you want to achieve Digital Transformation then you must realize these are issues of culture.
The Microsoft Technology Center is a service that helps customers on their Digital Transformation journey. We know that  successful data governance efforts are less about the technology and more about modern processes…and people. Data governance is changing to support dual mandates of heightened regulatory burdens and self-service initiatives. At the MTC, we’ve been doing this for years. We are thought leaders, conference speakers, and former consultants and executives. We’ve learned the patterns that will help you transform your governance programs. And with the Azure cloud and our governance technologies like Azure Purview, we can execute in hours-to-days instead of months.
successful data governance efforts are less about the technology and more about modern processes…and people. Data governance is changing to support dual mandates of heightened regulatory burdens and self-service initiatives. At the MTC, we’ve been doing this for years. We are thought leaders, conference speakers, and former consultants and executives. We’ve learned the patterns that will help you transform your governance programs. And with the Azure cloud and our governance technologies like Azure Purview, we can execute in hours-to-days instead of months.
Does this sound compelling? SUCCESS for the MTC is solving challenging problems for respected companies and their talented staff. Does that sound like folks you can trust with your data? The Digital Transformation is here, and we know how to help. Would you like to engage?
Are you convinced your data or cloud project will be a success?
Most companies aren’t. I have lots of experience with these projects. I speak at conferences, host hackathon events, and am a prolific open source contributor. I love helping companies with Data problems. If that sounds like someone you can trust, contact me.
Thanks for reading. If you found this interesting please subscribe to my blog.
Related Posts
- Data Literacy Workshops
- Software Implementation Decision Calculus
- MTC Data Science-as-a-Service
- Top 10 Data Governance Anti-Patterns for Analytics
- The Dashboard is Dead, Probably?
Dave Wentzel CONTENT
Data Architecture Digital Transformation