
MongoDB and CouchDB
 This my next post in my evaluation of NoSQL solutions. MongoDB is a document store that can persist arbitrary collections of data as long as it can be represented using a JSON-like object hierarchy. Mongo comes from the word "humongous", clearly indicating its intended purpose is for BigData. Rows (actually, records) look like JSON objects (really a binary representation called BSON). It falls in the "document store" class of NoSQL solutions.
This my next post in my evaluation of NoSQL solutions. MongoDB is a document store that can persist arbitrary collections of data as long as it can be represented using a JSON-like object hierarchy. Mongo comes from the word "humongous", clearly indicating its intended purpose is for BigData. Rows (actually, records) look like JSON objects (really a binary representation called BSON). It falls in the "document store" class of NoSQL solutions.
Schema-less
Mongo is touted by many to be schema-less. That's not true at all. The mere fact that it stores stuff in a JSON-like format clearly means that there is some modicum of schema to it. More appropriately you can think of Mongo as "a document database that enforces no schema". This is more than just a distinction without a difference...we'll come back to this again soon.
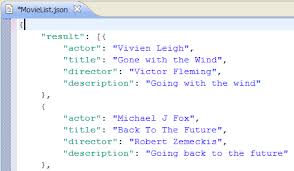
(a JSON example)
What an RDBMS Guy Needs to Know About MongoDB
- does not support locking. All updates are done at the singleton document level so locking really isn't needed. There are no bulk updates. This can of course lead to some interesting affects that you need to be aware of if you are using optimistic concurrency semantics (more on these issues below).
- MongoDB does not always respect atomicity (when it counts)
 Many claim Mongo does not support transactions. I disagree. The transaction is really the single document. You'll never have a partial document committed...it is all or nothing. However, if you insert multiple documents in one pass, each will be their own transaction.
Many claim Mongo does not support transactions. I disagree. The transaction is really the single document. You'll never have a partial document committed...it is all or nothing. However, if you insert multiple documents in one pass, each will be their own transaction. - does not define transactional integrity or isolation levels during concurrent operations. So it’s possible for processes to step on each other’s toes while updating a collection.
- Only a certain class of operations, called modifier operations, offers atomic consistency. These are equivalent to ALTER TABLE (schema change) commands. However, this is even only true when the metadata (or schema) operation is a "remove" or "rename". If you are adding a field, for instance, to your collection, then that is don't without concern for atomicity. As a side note I kinda find this funny. Mongo is often thought of as a schema-less solution yet I see some definite schema operations here.
- The lack of isolation levels also sometimes leads to phantom reads. Cursors don’t automatically get refreshed if the underlying data is modified. By default, MongoDB flushes to disk once every minute. That’s when the data inserts and updates are recorded on disk. Any failure between two synchronizations can lead to inconsistency. You can increase the sync frequency or force a flush to disk but all of that comes at the expense of some performance.
- You can query on nested attributes. This makes querying hierarchies much easier than in the relational world. Also, you can represent hierarchies in a document model much more "visually" than in normalized relational model.
- Mongo was built to scale-out, whereas RDBMSs are generally built, first and foremost, to scale up. Partition-tolerance is built-in. Sharding is built-in.
- Data that is duplicated across nodes are called "replica sets".
- An "insert" of a new record is auto-assigned the equivalent of a 12 byte GUID. This is mandatory to support partitioning.
- Mongo doesn't handle joins very well. Avoid modeling data that will require "joins". This is often easier said then done. Just like in the relational world, you may be years into a project when you notice that your data model either doesn't perform or isn't sound. To overcome this in Mongo you can use a "references" construct to give you a lookup to another collection.
- Most programmers like strict typing...ie, pick the best datatype, and enforce it, for your needs. You won't get that from Mongo. Everything is a string, mostly, and since it is "schema-less" you won't even get warnings/errors if you spell a field name wrong when querying. You must handle these things. So...I make the argument that Mongo might be diametrically opposed to strict-typing principles. Further, using a strongly-typed language against Mongo kinda defeats the purpose. A loosely-typed language like PHP or Python might be better choices. But you can certainly disagree with this assessment.
Differences with CouchDB
 CouchDB is very similar to MongoDB. Like Mongo the document is a key-value JSON-like document. It scales very well (runs on my Android device). Futon is its web interface and it can be queries using the standard cURL suite. Like MongoDB, each document has "_id" field which is the never-changing "primary key".
CouchDB is very similar to MongoDB. Like Mongo the document is a key-value JSON-like document. It scales very well (runs on my Android device). Futon is its web interface and it can be queries using the standard cURL suite. Like MongoDB, each document has "_id" field which is the never-changing "primary key".
| Property | MongoDB | CouchDB |
|---|---|---|
| Horizontal scalability | better than Couch | has no sharding. It instead uses multi-master replication.During a data conflict a deterministic winner is always chosen, but the loser's data is maintained as well as another version of the data, which can be queried using the "_rev" field. This is very nice. |
| Updates to a document | done "in place" | the updated document will be blanked and the _id retained, followed by an INSERT of a new document with a new _id. That can lead to a lot of confusion if you are relying on _id to never change. Don't do that. |
| Indexing, aggregation, caching | Has its own processes for indexing and aggregation | done via MapReduce. The mappers and reducers output is not discarded after being run. The output is cached until a change to a document would invalidate the output. |
GridFS
The maximum Mongo document size is 4MB. So it isn't well suited for large blobs. Instead, you use tricks not unlike what many data professionals do in the RDBMS world. You save a "pointer" to the blob with the original document/row. GridFS is the feature, generally, that allows large blobs of data to be saved outside of the document, yet still allow the document to be quickly searchable. The driver handles this for you so you don't need to know GFS intimately, or even understand it at all, to leverage it.
Final Thoughts
Avoid ad hoc queries against document stores. The performance tends to be horrendous.
Dave Wentzel CONTENT
data architecture nosql