
Parallel Data Warehouse as a NoSQL Alternative
 Another post in my NoSQL series...this one on Microsoft's Parallel Data Warehouse...PDW for short. This is an installed appliance delivered right to your door with everything completely setup for you.
Another post in my NoSQL series...this one on Microsoft's Parallel Data Warehouse...PDW for short. This is an installed appliance delivered right to your door with everything completely setup for you.
PDW’s PolyBase technology enables you to query Hadoop data and merge it with your relational data by using Transact-SQL and without learning a host of new skills. By using PolyBase’s Transact-SQL interface you can do more in-depth data mining, reporting, and analysis without acquiring the skills to run MapReduce queries in Hadoop. For example, queries can combine Hadoop and PDW data in a single step, Hadoop data can be stored as relational data in PDW, and query results can be stored back to Hadoop
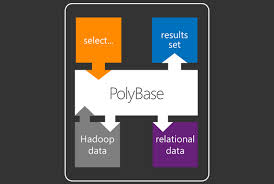 Query processing is highly parallelized. User data is distributed across processing and storage units called Compute nodes. Each Compute node has its own direct attached storage, processors, and memory that run as an independent processing unit. The Control node is the brains of PDW and figures out how to run each user query in parallel across all of the Compute nodes. As a result, queries run fast
Query processing is highly parallelized. User data is distributed across processing and storage units called Compute nodes. Each Compute node has its own direct attached storage, processors, and memory that run as an independent processing unit. The Control node is the brains of PDW and figures out how to run each user query in parallel across all of the Compute nodes. As a result, queries run fast
This is truly MPP (massively parallel processing) vs traditional RDBMS' which are SMP (symmetric mutliprocessing). Architecturally this is much closer to BigData. I wish I had an appliance to place with this.
Dave Wentzel CONTENT
sql server data architecture nosql