
Why isn't my Java catching SQL errors...or...How I learned to stop worrying and love the ring_buffer target
Today's Story
"Hey Dave, I found a bug in SQL Server."
I hadn't even sat my bad down yet. This was going to be one of those days. "I'll bet you did find a bug. SQL Server is horrendously buggy. We should migrate our app to Cassandra immediately."
Java Joe could detect the derision and changed his tack. "Well, can you check out this code for me. Clearly it throws as error in SSMS but not when I call it from Java.
(At this point I'll save you from viewing the Java. Essentially this was the code and, yep, the Java was not, indeed, throwing the very obvious error.)

Time to begin basic Java debugging. "Have you tried this code from SSMS and if so, did it throw the error correctly?" I already knew the answer, but I wanted to lead Java Joe down the troubleshooting path.
"Yes I did and it errors correctly in SSMS, just not in Java which is why I thought maybe it was a bug in a SQL Server driver somewhere. jdb does not show the error in the stack either. I'm at a loss so I was hoping you could look."
"Just because you don't see the error using jdb doesn't mean the error isn't coming back from SQL Server in the output. The simple fact is, we use so many "middleware" components in our applications that somewhere, somehow, one of those is hoovering the error without re-throwing it to the next  tier. We use jdbc drivers, both 2.0 and 3.0 at places, websphere, jdo/kodo in places, hibernate, ruby, groovy, highly-customized versions of Spring, as well as our own in-house developed DAO (data access objects) factory. There's probably even more layers between the user and the database error that I'm not aware, forgot, or am repressing. Somewhere in one of those layers you have the equivalent of an old VB "On Error Resume Next" (arguably, a FINALLY block) and you don't know it. "
tier. We use jdbc drivers, both 2.0 and 3.0 at places, websphere, jdo/kodo in places, hibernate, ruby, groovy, highly-customized versions of Spring, as well as our own in-house developed DAO (data access objects) factory. There's probably even more layers between the user and the database error that I'm not aware, forgot, or am repressing. Somewhere in one of those layers you have the equivalent of an old VB "On Error Resume Next" (arguably, a FINALLY block) and you don't know it. "
This is common sense to me but I knew I would have to prove this fact to Java Joe. "You see, this is a basic syllogism of error handling. SQL throws an error, Java does not throw it. Therefore, the problem is somewhere higher on the stack."
I didn't quite have Java Joe convinced. "But I tried everything and I beg to differ but there is nothing wrong with any of our tiers. Is there any way you can do some magic on SQL Server to ensure that the database engine is really throwing the error? Maybe SQL Server DDL errors are not passed to any non-SSMS utilities, or something."
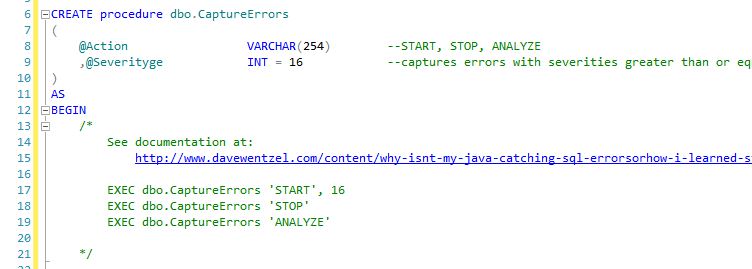
Ah, programmers are often scared of their debuggers. At this point I would generally get angry, but I already had a simple utility in my toolbelt ...an extended Events script.
And here is the important stuff:

Note that we are creating a ring_buffer TARGET to capture any error_reported event with the given severity. You can download the script here.
Extended Events Targets
I see a lot of people that hate the ring_buffer target. I really couldn't agree more that there are issues with it, specifically:
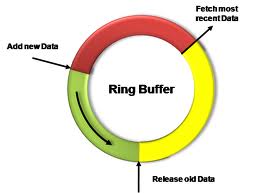 You can lose data. The ring_buffer is a "FIFO ring buffer" of a fixed memory size. So, in some situations you may miss some captured data because it was forced out. But this shouldn't be a surprise. It is called a "ring buffer" for a reason. Caveat emptor!
You can lose data. The ring_buffer is a "FIFO ring buffer" of a fixed memory size. So, in some situations you may miss some captured data because it was forced out. But this shouldn't be a surprise. It is called a "ring buffer" for a reason. Caveat emptor!- No GUI. You have to parse the XML which can be tedious. But that's why we have pre-package scripts to help us.
So, yep, those are some good reasons why you shouldn't RELY on the ring_buffer for important work. But when I hear that people HATE something the contrarian in me wants to know when I should LOVE it.
Reasons to Love the ring_buffer Target
I've found two really good uses for the ring_buffer that may help you out.
- When I need to capture some data for trending purposes and I don't mind losing it under adverse scenarios.
- Finding errors being thrown real time, such as my allegory above.
ring_buffer Usage for Trending
Example: saving deadlocks for later analysis. The ring_buffer has a set max_memory and when that is reached the oldest events are purged, FIFO-style. Some deadlock graphs are huge and can fill the ring_buffer quickly.
Why not just use event_file then and not have to deal with ring_buffer issues?
- Not everyone has the necessary filesystem access to their SQL Servers to write and delete files.
- If you are tracing a lot of events you risk writing huge event_files. If your Ops Guys monitor your servers it won't be long before they want to know what is going on.
- Big event_files are slow to query.
 If you don't have these issues then PLEASE consider using event_file instead. Murphy's Law says that even though you don't NEED your trend data now, when you experience severe issues someday you'll curse choosing the ring_buffer when it loses a good chunk of your forensic data.
If you don't have these issues then PLEASE consider using event_file instead. Murphy's Law says that even though you don't NEED your trend data now, when you experience severe issues someday you'll curse choosing the ring_buffer when it loses a good chunk of your forensic data.
My PerformanceCollector utility uses ring_buffer to look for any deadlocks. On a schedule it will write the contents of the ring_buffer to a permanent table and restart the ring_buffer. If a few deadlocks roll off the end of the ring_buffer I really don't care. I'm monitoring for deadlocks to look for trends...basically, bad data access patterns that we've introduced into our application that we need to fix before they get out of control.
Watching Errors Real Time
So back to our story...Java Joe needed hard evidence that an error was indeed being thrown, as well as what the actual error was. I had already prepared a stored procedure for just this purpose (Java Joe wasn't the first developer to have this problem...Ruby Ray had a similar problem weeks before). The stored proc takes a parameter of START, STOP, or ANALYZE. You definitely don't want this running 24x7 since EVERY error thrown will be logged. You need to run ANALYZE BEFORE you run STOP. The process of stopping a ring-buffered session wipes out the buffer which means your data is gone.
Let's look at our example
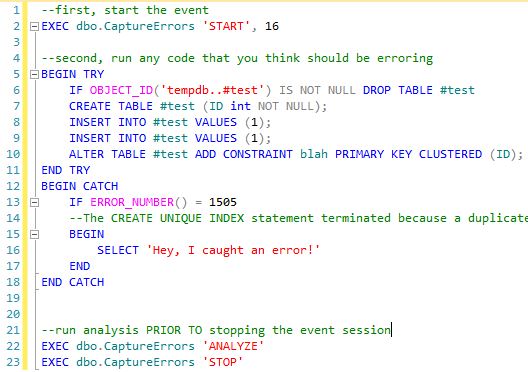 Here is our example code again, except this time I annotated it to show the basic workflow.
Here is our example code again, except this time I annotated it to show the basic workflow.
- Start the event session. Choose an error severity that you need. The default is 16.
- run whatever code (or your application) that should be generating errors that you wish to see
- run
ANALYZEwhich will generate the output below. - run
STOPto stop the event session. This will save some system resources and about 4MB of memory.
So, what is the output?
The proc outputs two result sets. One lists all of the "error_reported" events that were thrown. The second decodes the XML a bit to make it easier to look at exactly what the errors were.
Let's take a look at the data.
Note that we actually threw two errors.
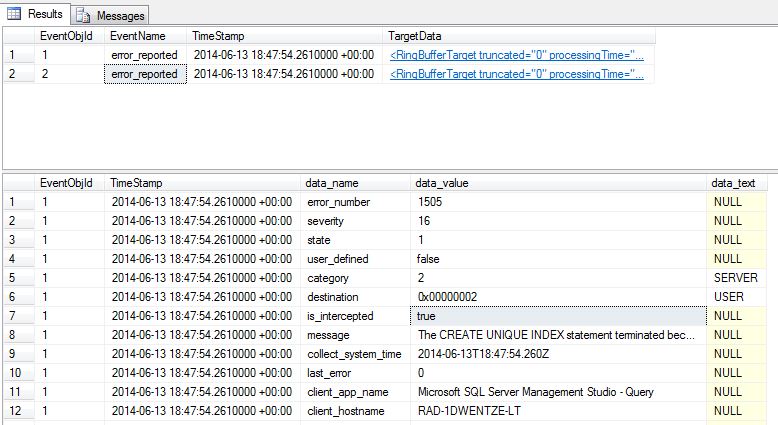
Huh?
This is actually expected based on how I constructed the example. The first error is 1505 (row 8 above). The second, not in the screenshot above, is error 1750 (Could not create constraint. See previous errors.).
And that is exactly what I would expect.
Summary
Occasionally you may find yourself in need of capturing errors that are occurring on a running system real-time. The way to do this is to use Extended Events. But the rigamarole required to set up an event session that logs to a file, and then have to query that file, can be cumbersome. Sometimes you just need something quick and dirty. For those times a ring_buffer target works wonderfully. The example above I've used NUMEROUS times to assist developers who are scared of their debuggers to see actual SQL Server errors that are somehow being goobled up in one of their data access technologies.
You have just read "Why isn't my Java catching SQL errors...or...How I learned to stop worrying and love the ring_buffer target" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
sql server performancecollector