
UPDATE FROM syntax and LEFT JOINs and ambiguity
If you use SQL Server you've probably seen code like this:
| UPDATE dbo.tab SET SomeCol = table2.SomeOtherCol FROM dbo.tab JOIN dbo.table2 ON tab.ID = table2.ID |
To us SQL Server people this code makes perfect sense...update some values in the first table with rows from a second table. It surprises many SQL Server people when exposed to Oracle for the first time that this is not valid ANSI SQL syntax. I don't want to make this an Oracle post, but there are solutions to the "update one table with values from a second" pattern that work in Oracle. They will usually perform just fine, my only complaint would be that the Oracle syntax is not nearly as easy to convert from a SELECT to an UPDATE so I can "test before executing". What I mean is...in my UPDATE statement above I could change the first line to "SELECT table2.SomeOtherCol, tab.ID" and execute it to see exactly what rows I will be changing.
That is not a jab against Oracle. An Oracle purist will counter that the UPDATE...FROM TSQL syntax is frought with danger. I agree, and that is what this post is about. Let's look at some code:
| CREATE TABLE #Foo (ID int, colA varchar(20)) CREATE TABLE #Bar (ID int, FooID int, colB varchar(20)) INSERT INTO #Foo VALUES (1,'FooRow1') INSERT INTO #Foo VALUES (2,'FooRow2') INSERT INTO #Foo VALUES (3,'FooRow3') INSERT INTO #Foo VALUES (4,'FooRow4') INSERT INTO #Bar VALUES (1,1,'BarRow1') INSERT INTO #Bar VALUES (2,2,'BarRow2') INSERT INTO #Bar VALUES (3,2,'BarRow3') INSERT INTO #Bar VALUES (4,2,'BarRow4') |
Requirement: Set #Foo.colA equal to *any value* from #Bar.colB, if there is a value available for the given key. A contrived example to be sure.
| BEGIN TRAN UPDATE #Foo SET colA = Bar.colB FROM #Foo Foo LEFT JOIN #Bar Bar ON Foo.ID = Bar.FooID select * from #Foo ROLLBACK TRAN |
It should be obvious that #Foo.ID = 1 will be set to 'BarRow1' since there is only one lookup row. It should also be obvious that #Foo.ID rows 3 and 4 will be set to NULL since there are no corresponding keys in #Bar for those FooIDs.
What is less clear is what will happen to #Foo.ID = 2 ... will it be set to 'BarRow2', 'BarRow3' or 'BarRow4'? There is ambiguity here. In Oracle-land, the equivalent query (written of course without a LEFT JOIN) would throw "ORA-01427: single row subquery returns more than one row." Exactly. And really, isn't that what SQL Server should be throwing? Many people have petitioned Microsoft to deprecate UPDATE...FROM (and DELETE...FROM, which has the same issues) syntax for this reason (as well as some other reasons). It's become something akin to a religious war. With people on both sides of the debate.
I personally like the UPDATE...FROM syntax, mostly because it's simple to convert to SELECT and test. It's the UPDATE...FROM...LEFT JOIN syntax that gets tricky. There are two reasons we might use LEFT JOIN in an UPDATE statement:
- I don't want to restrict the rows I wish to act on, rather I want to assume NULL if the LEFT JOIN was not satisfied. This is safe and unambiguous in my mind. This is also the requirement listed above for this blog post.
- I want to LEFT JOIN but I may have *many* LEFT JOIN table rows for each *one* key row from the FROM table. In other words, a 1:M relationship. This is also part of my requirement above.
In that case, which is my example above, what will be the final value for colA for ID 2? Here you go:
BEGIN TRAN | 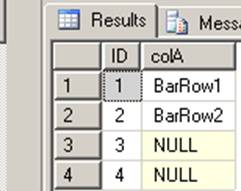 |
Before you jump to the conclusion that "I'll always get the first matching row back", remember that there is no concept of row ordering in an RDBMS unless there is a specific ORDER BY clause applied. Never assume order. Don't believe me? Let's modify our code to add a CLUSTERED INDEX strategically:
BEGIN TRAN | 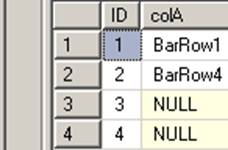 |
Oops. Note that colA's value has changed due to the new ordering inferred by the clustered index!
So far, so good. I still don't see the big deal with UPDATE...FROM syntax *if* you understand the issues above. Ah, but that's the rub. Too often I see code like this:
| BEGIN TRAN UPDATE #Foo SET colA = (SELECT TOP 1 colB FROM #Bar Bar WHERE Bar.FooID = Foo.ID) FROM #Foo Foo select * from #Foo ROLLBACK TRAN |
What is this code trying to do? Very simply, it is bringing back the FIRST row from Bar that has the given FooID, using a correlated subquery. I'm not a mind reader, but the developer was probably thinking, "I have a situation where I am bringing back possibly more than one row for the given key, I better restrict it since I don't really understand what SQL Server will do. I can accomplish that by using a TOP clause."
I have problems with this approach:
- You still haven't guaranteed *which* key will be returned (although that's not part of our requirement, it's still ambiguous and you shouldn't code ambiguity if possible).
- You've taken a FROM...LEFT JOIN syntax that the optimizer will be able to handle in a performant manner and replaced it with a TOP clause in a correlated subquery. Correlated subqueries *often* perform far worse than straight JOINs (especially against larger tables...this is the RBAR effect). Also, TOP clauses incur the overhead of a SORT operator.
- It's not as easy to read or convert from a SELECT statement that I can test to an UPDATE.
If the requirement were changed to return "the most recent entry from #Bar" then the TOP solution might be acceptable over smaller result sets, assuming of course the addition of an ORDER BY clause.
Takeaways
- If you use UPDATE...FROM syntax be aware of ambiguities.
- If you use UPDATE...FROM...LEFT JOIN be aware that you have ZERO control over which row from the LEFT JOIN'd table will be returned if you have a 1:M situation.
[[TSQL]]
Dave Wentzel CONTENT
sql server data architecture oracle