
Sharding
This is my next post in my NoSQL series. Sharding is not specific to NoSQL, but quite a few BigData/NoSQL solutions use sharding to scale better.
What is sharding?
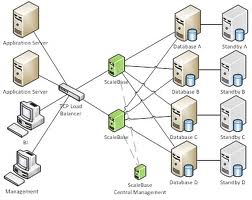 A shard is one horizontal partition in a table, relation, or database. The difference between a shard and horizontal partitioning is that the shard is located on a separate network node. The benefit of sharding is that you will have less data on each node, so the data will be smaller, more likely to be held in cache, and the indexes will be smaller. Most importantly, I can now use a grid of nodes to attack queries across shards. This is an MPP architecture vs a SMP architecture (massively parallel processing vs symmetric multi processing). You can also view this as sharding is "shared nothing" vs horizontal partitioning which is generally "shared almost everything."
A shard is one horizontal partition in a table, relation, or database. The difference between a shard and horizontal partitioning is that the shard is located on a separate network node. The benefit of sharding is that you will have less data on each node, so the data will be smaller, more likely to be held in cache, and the indexes will be smaller. Most importantly, I can now use a grid of nodes to attack queries across shards. This is an MPP architecture vs a SMP architecture (massively parallel processing vs symmetric multi processing). You can also view this as sharding is "shared nothing" vs horizontal partitioning which is generally "shared almost everything."
Sharding works best when each node (or the central query node in some cases) knows exactly which shards a given data element would reside on. Therfore the shard partition key must be a well-defined range. You want your shards to be well-balanced and often that means using a contrived hash key as the shard key, but this is not a requirement.
What products use sharding?
This is not a comprehensive list, but:
- MySQL clusters use auto-sharding.
- MongoDB
- Sharding is not so useful for graph databases. The highly connected nature of nodes and edges in a typical graph database can make it difficult to partition the data effectively. Many graph databases do not provide facilities for edges to reference nodes in different databases. For these databases, scaling up rather than scaling out may be a better option. I'll talk more about graph databases in a future NoSQL blog post.
Problems with sharding
The concept of sharding is nothing new. The biggest problem is when you attempt to roll your own sharding. I've seen this a lot and it never works. Invariably the end result is a bunch of code in the app tier (or ORM) that tries to determine which shard should have a given data element. Later we determine that the shards need to migrate or be re-balanced and this causes a lot of code changes.
Dave Wentzel CONTENT
data architecture nosql