
PostgreSQL for the SQL Server Guy
PostgreSQL is an open source RDBMS that is very similar to SQL Server. In this post I'll compare the features and syntax of the two. Learning a new DBMS tool can be a lot of fun and will help you understand SQL Server even better.
I've been using PostgreSQL a lot lately and I'm really loving it. Whenever I learn a new database manager I like to compare its general features to what I already know best, namely SQL Server and Oracle. I did an entire blog series on Vertica where I compared its features to SQL Server's and dove deeper where Vertica had compelling features. I'm not going to go into that much detail with Postgres.
Who cares?
If you are a SQL Server Guy, you may be wondering why you should bother learning Postgres? Very simple. When you learn a new database manager  you begin to think critically, or at least differently, about SQL Server. For instance, Oracle has no concept of "clustered indexes", yet their queries don't need them. Why is that? Well, when you learn the Oracle architecture you discover that something like "a sorted table" really isn't all that important. Another example...Oracle DBAs never bother "reindexing" their tables. For years that was a standard practice in the SQL Server world. Only recently have DBAs stopped reindexing their tables. Why? They realized, like Oracle people have known for years, that in most cases if you have fragmentation you really don't need to worry about unless you have a scan-heavy workload. Fragmentation doesn't matter for seeks. And if you have heavy fragmentation with a scan-heavy workload, the better fix involves changing your FILLFACTORs (known as PCTFREE in Oracle) as well as your general design.
you begin to think critically, or at least differently, about SQL Server. For instance, Oracle has no concept of "clustered indexes", yet their queries don't need them. Why is that? Well, when you learn the Oracle architecture you discover that something like "a sorted table" really isn't all that important. Another example...Oracle DBAs never bother "reindexing" their tables. For years that was a standard practice in the SQL Server world. Only recently have DBAs stopped reindexing their tables. Why? They realized, like Oracle people have known for years, that in most cases if you have fragmentation you really don't need to worry about unless you have a scan-heavy workload. Fragmentation doesn't matter for seeks. And if you have heavy fragmentation with a scan-heavy workload, the better fix involves changing your FILLFACTORs (known as PCTFREE in Oracle) as well as your general design.
Do you see how we can all learn from each other?
It's also very common to meet experts ofother DBMS vendor technologies who will spout lies and misconceptions about SQL Server. You don't want to be one of those people. When someone spouts a stupid comment you want to be knowledgeable enough about the competition to be able to refute those lies. Don't just be the SQL Server Guy who hates Hadoop...be the SQL Server Guy who hates Hadoop for valid, innumerable reasons. Don't be ignorant of a technology which then causes you to make stupid statements.
The following tables list the key features of any RDBMS and then compares SQL Server to PostgreSQL. This is not meant to be an exhaustive list. Just something to whet your appetite.
General Features
| Feature | SQL Server | PostgreSQL |
|---|---|---|
| Pronunciation (you don't want to sound "uninformed" when you discuss a technology) | "sequel server" | "POST grez" or "Post grez Queue El" |
| Licensing | Anywhere from "free" (SQL Express) to super-expensive | similar to MIT or BSD. Very liberal (no attribution is even required). Postgres' biggest open source competitor is probably MySQL, which is GPL-licensed. IMO, GPL licensing can be dangerous for ISVs. See [[Open Source Licensing]]. |
| default port number (defined with IANA) | 1433 | 5432 |
| determine the version | select @@version | SELECT version(); |
| Primary GUI administration/query tool | SSMS | pgAdmin |
| command line query execution tool | sqlcmd/osql | psql |
| redo transaction logs | transaction logs (.ldf files) | write-ahead logs (WAL)...very similar to Oracle's redo logs |
| recovery mode | FULL or SIMPLE | archive_mode = on is the same as FULL. |
| transaction isolation and concurrency semantics | various, but mostly READ COMMITTED AND SNAPSHOT ISOLATION are the most common | MVCC (multi-version concurrency control) which is identical to RCSI (including the concept of the row version store) |
(pgAdmin screenshot)
Basic DBA Tasks
| Feature | SQL Server | PostgreSQL |
|---|---|---|
| Primary Backup Method | BACKUP DATABASE which creates a self-contained backup | hot physical backups of files with continuous archiving. This closely resembles Oracle's hot backups. Postgres, nor Oracle, has a concept similar to SQL Server's backup method. You essentially take each "file" offline and use scp, rsync or any other copy tool to copy it elsewhere, as well as the write-ahead logs (WAL). |
| Logical Backups | SQL Server has no concept of this natlvely. Maybe something like "copy database wizard" | Logical recovery executes SQL to re-create the database objects. pg_dump > outfile.sql generates the dump...psql dbname < infile.sql restores the .sql file. Oracle works identically. pg_dump simply executes SQL statements against the database to unload the data. The data is consistent, thanks to MVCC, as of the point-in-time when pg_dump started. You can restore this data and then apply the WAL. But you can restore selective lists of objects, schemas, or just structure and no data, etc etc. |
| Replication | Yes | Has similar feature set to SQL Server. |
| "Log Shipping" | Yes | Very similar. The "hot physical backup files" are copied to the destination and then the WAL files are copied automatically when they "roll over". Also called "log shipping" |
| Can queries run on Log Shipped database? | Yes, if db is in STANDBY mode. Queries must be quiesced whenever log backups are restored | Yes. This is called "hot standby" or "continuous replication". In fact, unlike SQL Server, Postgres allows the queries to continue running while the logs are being applied. |
Programming Features
| Feature | SQL Server | PostgreSQL |
|---|---|---|
| main procedure language | Transact-SQL | PL/pgSQL. This is so similar to TSQL that you can pick it up in just a few minutes. |
| Alternate Languages | Anything that can produce CLR code | PL/Perl, PL/Python and tons more. |
| CREATE OR REPLACE syntax | No. Have to query sys.objects and DROP then CREATE the object | supports this feature for most db objects. This is soooo much easier. Microsoft, when will you fix this? |
| metadata schema | sys. or information_schema. | information_schema. or pg_* tables |
| hierarchy of objects | host-->server instance-->database-->schema-->object | host-->server instance-->database-->schema-->object |
| list all databases on the instance | select name from sys.databases; | select datname from pg_database; |
| object identifiers | [table] (preferred) or "table" depending on quoted_identifiers setting | object names can contain spaces and mixed case characters if enclosed in double quotes. Otherwise object names are assumed to be lower-cased. If you create your objects using quoted names, then you need to write your SQL using quoted names. Converts all non-quoted names to lowercase when used within an SQL statement. This can be tricky. It's best to keep all object names in lower case only. |
| data loading tool | bcp | \COPY something FROM something.txt CSV HEADER or use pgloader which is a bit more friendly. |
| windowing functions | row_number() over() | same. all windowing functions from SQL Server are present in Postgres. In fact, Postgres is even richer. |
| cte's, recursive cte's, updateable cte's | Postgres works identically to SQL Server |
Some Example PL/pgSQL Code
CREATE OR REPLACE FUNCTION fn_constraint_exists (text) RETURNS integerAS $$BEGINIF EXISTS (SELECT 1 FROM pg_constraint WHERE conname = $1) THENRETURN 1;ELSE RETURN 0;END IF;END
$$ LANGUAGE plpgsql;That's very close to TSQL. Interesting stuff:
- $$ as a delimiter where you declare the actual language you are using for the code.
CREATE OR REPLACE...I love that feature.- arguments can be named or position (where you only declare the datatype, like above). You reference positional parameters using $n syntax.
IF...THEN...ELSE...ENDIF I think is cleaner than TSQL's method
Finally...
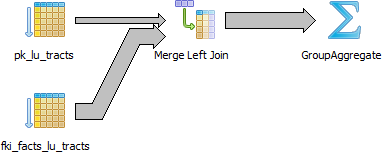
(a graphical EXPLAIN PLAN in pgadmin...looks pretty much like a SQL Server graphical plan)
You have just read "[[PostgreSQL for the SQL Server Guy]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed.

Dave Wentzel CONTENT
postgres sql server data architecture