
Pattern: Overcoming Deferred Name Resolution When Using Stored Procs for Code Reusability
I hate Deferred Name Resolution in SQL Server mostly because it is inconsistent. If you don't know what DNR is, see this article. In a nutshell, I can create a stored proc that references a non-existent table, but I can't reference a non-existent column in an existing table. Here's a simple proof:
USE tempdb
IF NOT EXISTS (select * from sysobjects where id = object_id('Foo'))
PRINT 'Foo does not exist, OK'
GO
CREATE PROC BAR AS SELECT ID FROM Foo
GO
SELECT name, type FROM sysobjects WHERE name = 'BAR' and type = 'P'
GO
DROP PROC BAR
GO
And the output...
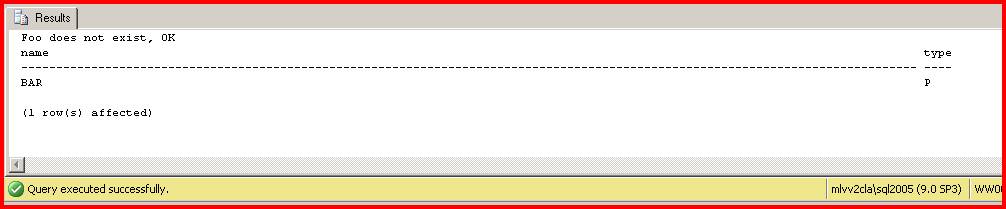
...confirms that I could create a proc referencing a non-existent table. But now let's create the table first but reference a non-existent column:
USE tempdb
CREATE TABLE FOO (colA varchar(100))
GO
CREATE PROC BAR AS SELECT ID FROM Foo
GO
SELECT name, type FROM sysobjects WHERE name = 'BAR' and type = 'P'
GO
DROP TABLE FOO
GO
DROP PROC BAR
GO
And the screenshot shows that we failed.
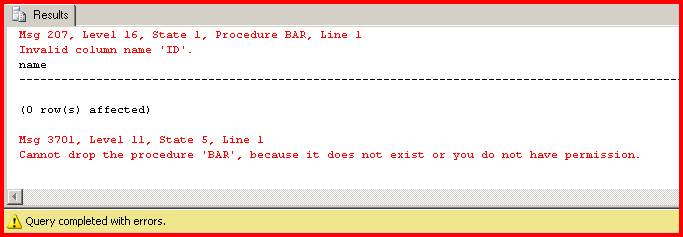
It seems ridiculous to me that I can create a proc referencing a non-existent table, but can't reference a table with a non-existent column. You may be saying, "So what? Why would I ever want to reference a non-existent column?"
Code Reusability and Temp Tables
...that's why. It's good OO programming design to not copy/paste code everywhere. Unfortunately in TSQL we often have to do that if we expect performance to be acceptable. Many people take their copy/paste logic and insert into into a scalar UDF. That won't work if you want peformant code since the scalar UDF is processed in RBAR (row by agonizing row) fashion. An inline table valued function will work, the optimizer will treat the TVF as a kind of "macro" and will expand the code in a performant manner. But there are limitations to this approach that make it's use very limited.
The best approach, by far, in my opinion, is to pass around temp tables into stored procs that are in essence the TVF code, or code you don't want to copy/paste everywhere. So, let's assume you have a complex calculation that you run over a series of table ids in various procedures that you would like to reuse in a performant manner.
- First create a temp table that holds the Ids and a placeholder col for the calculation.
- Then build a utility procedure that looks for that temp table and performs the calculation
- Now in any routine that needs that calculation simply make a call to first build the temp table, then call the utility procedure.
The whole process should look something like this:
USE tempdb
GO
CREATE PROC Utility AS
BEGIN
UPDATE #tblUtility SET calc = round(PI(),4)* ID --you're calculation logic goes here
WHERE ID % 2 = 0
END;
GO
CREATE PROC Caller AS
BEGIN
--I'm building my list of IDs that I need into my temp table
CREATE TABLE #tblUtility (ID int, calc decimal(13,4))
INSERT INTO #tblUtility SELECT TOP 5 object_id, NULL FROM master.sys.objects
EXEC Utility
SELECT * from #tblUtility
END
GO
EXEC Caller
GO
DROP Proc Utility
GO
DROP Proc Caller
GO
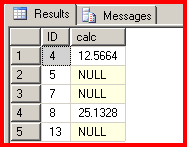
Very simple and elegant. The problem comes in where I want to do a lot of calculations in my Utility procedure, hence I need a lot of columns, let's assume we need 20 columns declared. We now have to copy/paste those 20 column declarations into every Caller procedure. That's redundant code. The simple solution is to only declare the basic table in Caller with just the ID col, then ALTER the table in the Utility procedure to ADD the calculation columns. That's much less copy/paste code. And much less work when we need to change or add new cols in the future. We don't need 20 new columns to see how the improvement would work. Using our example, this should be much easier to maintain:
USE tempdb
GO
CREATE PROC Utility AS
BEGIN
ALTER TABLE #tblUtility ADD calc decimal(13,4) --note that any calc cols are created here
UPDATE #tblUtility SET calc = round(PI(),4)* ID --you're calculation logic goes here
WHERE ID % 2 = 0
END;
GO
CREATE PROC Caller AS
BEGIN
--I'm building my list of IDs that I need into my temp table
CREATE TABLE #tblUtility (ID int) --note only the ID col is needed here
INSERT INTO #tblUtility SELECT TOP 5 object_id FROM master.sys.objects
EXEC Utility
SELECT * from #tblUtility
END
GO
EXEC Caller
GO
DROP Proc Utility
GO
DROP Proc Caller
GO
But it doesn't work, thanks to our old friend Deferred Name Resolution.

Essentially this is telling us that the UPDATE cannot occur because a column does not exist in an existing table. Two solutions come to mind:
- We use dynamic SQL in the Utility procedure for the actual UPDATE statement. This works because the column will be added to the table by the time DNR kicks in when the dynamic SQL is executed. I don't like dynamic SQL so I don't like this solution.
- Create a second "layer" of Utility procs that handle DNR goofiness. In practice the Utility proc will merely have the ALTER...ADD commands. It will then call into subprocedures that will have the actual calculation logic.
Assuming we go with Option 2, this is what the new Code Reusability Pattern would look like:
USE tempdb
GO
CREATE PROC Utility AS
BEGIN
ALTER TABLE #tblUtility ADD calc decimal(13,4) --note that any calc cols are created here, in the first level util proc
EXEC Utility_SubProc_Calculations
END;
GO
CREATE PROC Utility_SubProc_Calculations AS
BEGIN
UPDATE #tblUtility SET calc = round(PI(),4)* ID --you're calculation logic goes here, in the subproc
WHERE ID % 2 = 0
END;
GO
CREATE PROC Caller AS
BEGIN
--I'm building my list of IDs that I need into my temp table
CREATE TABLE #tblUtility (ID int) --note only the ID col is needed here
INSERT INTO #tblUtility SELECT TOP 5 object_id FROM master.sys.objects
EXEC Utility
SELECT * from #tblUtility
END
GO
EXEC Caller
GO
DROP Proc Utility
GO
DROP Proc Utility_SubProc_Calculations
GO
DROP Proc Caller
GO
Pattern Summary
The key to performant TSQL code reusability, in my opinion, is utility procedures. To get the most benefit we need to create an "extra" layer of abstraction to handle the god-awful Deferred Name Resolution implementation of TSQL. You need to :
- Create a Utility procedure that simply ALTER...ADD columns to your temp table and calls a Utility_SubProc ...
- Utility_SubProc handles the actual calculations and update of the temp table.
- In any Calling procedures that want to utilize our Utility procedure we simply
- Add a call to CREATE TABLE #whatever with the only col being the ID
- Add a call to Utility
With this simple API pattern we overcome both DNR issues and Performant TSQL Code Reuse. [[Tips on Writing Better Stored Procedures|More Tips on Writing Better Stored Procedures]]
Dave Wentzel CONTENT
sql server data architecture