
MapReduce for the RDBMS Guy
MapReduce is a parallel programming framework for executing jobs against multiple data sets. MapReduce is the framework Google uses to query multiple nodes in a partition-tolerant datastore. Google owns the patent on the MapReduce framework, but the concepts are freely shared and there are a number of open-source implementations.

MapReduce's concepts come from the functional programming world. A map function applies an operation to each element in a list, generally returning another list. It takes a key-value pair and emits another key-value pair. Example...function "plus-one" applied to list [0,1,2,3,4] would yield a new list of [1,2,3,4,5]. The original list's data is immutable (never changed) and therefore I need not be concerned with concurrency and locking. So, multiple map threads could work on this list if the list could be partitioned across multiple nodes. The map function runs on each subset of a collection local to a distributed node. The map operation on any one node is completely independent on the same map operation running on another node. This isolation is how you get cheap, effective parallel processing. And if any node fails the map function can be restarted on a redundant node.
Functional programming also has the concept of a reduce function, more commonly known as a "fold function", but you sometimes hear them called "accumulate" or "inject" functions. A fold function applies a calculation on the key-value pairs and produces a single result. Almost like the SUM or AVG aggregate functions in RDMBS-land. A fold (or reduce) function on the list [1,2,3,4,5] would yield a result of 15.
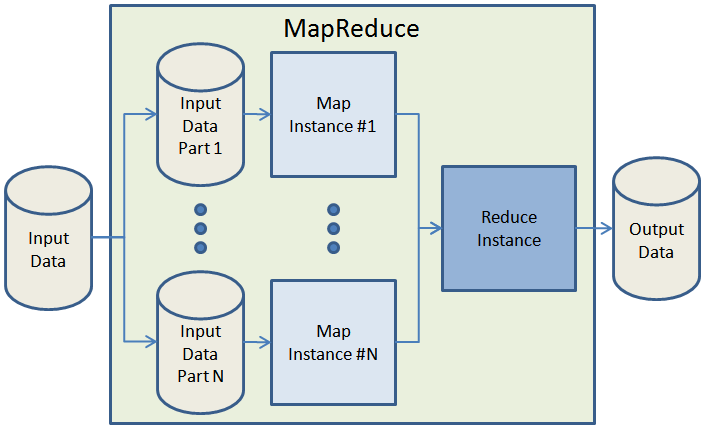 Map and Reduce functions are used together to process lists of data. The maps may run a simple calculation on many nodes of the datastore. The result may be piped to the reducer that may run on a single master node that generates the query's answer. The map generally must run before the reduce, but the underlying code generally runs computations in parallel.
Map and Reduce functions are used together to process lists of data. The maps may run a simple calculation on many nodes of the datastore. The result may be piped to the reducer that may run on a single master node that generates the query's answer. The map generally must run before the reduce, but the underlying code generally runs computations in parallel.
Maps and reduces can be thought of as algorithms. The maps are the relationships and hierarchies among the data. It is critical to performance that the maps are designed properly. A map will generally "scan" the data, much like an RDBMS index scan. Maps will generally not seek.
A map may pass its data to another map, there can be more than one map function prior to the reduce being called. Similarly, a reduce function can be the target of another reducer.
When your querying requirement gets more complex it is generally not a good idea to make you map and reduce jobs more complex. Instead you should have additional mappers and reducers. So, add more jobs vs making the existing jobs more complex.
A Better Example
Think of a partitioned datastore of Customers on 64 nodes. We want to know how many customers reside in Pennsylvania. A Java Jock working on a traditional RDBMS may do something stupid like bring back all customers from each node/database and then look for the "Pennsylvanias" on the client tier. That's wildly inefficient. With MapReduce the requester will issue a "map" to each node that says, "Please give me a count of your node's customer in PA". Each node sends the data back to the requester which "reduces" the responses by saying, "Now give me a sum of all nodes' counts." That's actually kinda efficient.
Is MapReduce that much different than what we do in RDBMSs today?
Dave Wentzel CONTENT
data architecture nosql