
IOPS
 Metrics are a funny thing. You hear people spout out metrics all the time. "My Page Life Expectencies are 200." "My disk latencies are 20 ms." Just regurgitating the given metric says nothing about context. There is no good guidance for PLEs or disk latencies and if you ask ten knowledgeable data professionals you'll likely get ten different answers. But put all of the opinions together and you'll get a good "feel" for what might be good and what might be bad. My general rule of thumb, I call it the "smell test", is if I don't have a benchmarked baseline for a metric then I look at "reasonable guidance". If my metric is close then I look at some other aspect of the system to tune. If my metric is wildly out of the range of reasonable guidance, then that is worth investigating further.
Metrics are a funny thing. You hear people spout out metrics all the time. "My Page Life Expectencies are 200." "My disk latencies are 20 ms." Just regurgitating the given metric says nothing about context. There is no good guidance for PLEs or disk latencies and if you ask ten knowledgeable data professionals you'll likely get ten different answers. But put all of the opinions together and you'll get a good "feel" for what might be good and what might be bad. My general rule of thumb, I call it the "smell test", is if I don't have a benchmarked baseline for a metric then I look at "reasonable guidance". If my metric is close then I look at some other aspect of the system to tune. If my metric is wildly out of the range of reasonable guidance, then that is worth investigating further.
Disk metrics are really tough. There is so much abstraction going on with a system hooked up to a SAN that any given metric could be normal even if it falls wildly outside of the norm. Latencies are one such metric. About a year ago I pinned down an MS SQL Server field engineer who stated what the then current latencies guidance was (10 ms). I blogged about that in my post [[Latency and IOPS]]. I had a harder time extracting that guidance than that Microsoft employee's dentist had extracting his abcessed tooth.
 At the time I was told that IOPS of 100 Page Reads/sec was the guidance for "high". We were at the time averaging 400 with sustained peaks over 4000. This guidance made sense to me at the time because I knew our database code was horrendous (too much tempdb bucketing in procedures, lousy index decisions, procedures that returned 64MB result sets, lots of PAGEIOLATCH_SH waits, etc) and I was working on fixing the most egregious things. So, using "Dave's Smell Test" I knew that our IOPS were probably outside of the norm and warranted further investigation.
At the time I was told that IOPS of 100 Page Reads/sec was the guidance for "high". We were at the time averaging 400 with sustained peaks over 4000. This guidance made sense to me at the time because I knew our database code was horrendous (too much tempdb bucketing in procedures, lousy index decisions, procedures that returned 64MB result sets, lots of PAGEIOLATCH_SH waits, etc) and I was working on fixing the most egregious things. So, using "Dave's Smell Test" I knew that our IOPS were probably outside of the norm and warranted further investigation.
Now, I've always thought IOPS was a kinda nebulous term. What is the definition of an IO? Is it a 4KB block, or a 64KB block, which is of course what SQL Server cares about. Depending on what the definition is your IOPS number could be off by a factor of 16. Clearly it is in the interests of the vendor to spout off the highest IOPS number possible in their marketing material...so do you think the published number is for 4KB or 64KB blocks? Read the fine print.
It just seems a bit too confusing, which is why I prefer my disk metrics to always be in terms of "latency", not IOPS. Your IO subsystem's goal should be, IMHO, the least amount of latency as possible, with the highest IOPS. This is why you'll often see DBAs ask for their HBAs to have higher Q depth settings than the factory defaults. Lower (default) Q depths will sacrifice some latency for better IOPS. That seems backwards to me on an OLTP system.
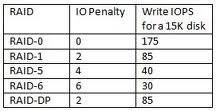 And then of course you have to take into consideration your "effective IOPS". This is a term I made up (I think anyway) and it takes into consideration whether you are using RAID and what RAID level. Single disk drives have a raw IOPS number. Using RAID 10 effectively halves your raw IOPS number. Why? An extra write is required for the mirror. It's twice as bad with RAID 5 ([[RAID 5 Write Penalty]]). For instance, SATA drives average about 150 IOPS. If I had 6 of those I would have about 900 IOPS, but I need to halve that number to get the true 450 IOPS at RAID 10. This is all theoretical and confusing which is why I tend to ignore IOPS.
And then of course you have to take into consideration your "effective IOPS". This is a term I made up (I think anyway) and it takes into consideration whether you are using RAID and what RAID level. Single disk drives have a raw IOPS number. Using RAID 10 effectively halves your raw IOPS number. Why? An extra write is required for the mirror. It's twice as bad with RAID 5 ([[RAID 5 Write Penalty]]). For instance, SATA drives average about 150 IOPS. If I had 6 of those I would have about 900 IOPS, but I need to halve that number to get the true 450 IOPS at RAID 10. This is all theoretical and confusing which is why I tend to ignore IOPS.
IOPS numbers tend to NEVER hit the published numbers, especially on rotational media. This is because database access tends to be somewhat random in nature. Sequential transaction log access is the exception. The more that disk head has to move, the worse the effective IOPS. That's another reason why I firmly believe that ALTER INDEX...REORGANIZE is one of the best ways to speed up your effective IOPS.
But even the latest SSDs will rarely give you IOPS numbers anywhere close to what they publish. You'll likely saturate the PCI-E bus first.
So I find myself not really relying on published IOPS or even "reasonable guidance". There is no substitute for measuring your disk subsystem yourself. Even so, once you have a good measurement, is there anything you can really do about it if it isn't up to the smell test? Other than changing HBA QDs or using local SSDs for tempdb, I haven't had much luck in my career getting IO subsystems upgraded, even when they were woefully under-spec'd/misconfigured given my measured latency and IOPS. The only thing I can ever really do is to lessen my reliance on IO. And that of course means good indexing, good data hygiene, good caching, adding RAM, and tweaking IO intensive queries.
Dave Wentzel CONTENT
sql server data architecture