
HP Vertica
 I've been using HP Vertica since before HP bought the company. I first wrote about Vertica in 2010 when I wrote about column-oriented databases. I'm again using Vertica in my daily responsibilities and I decided to try to get my Vertica certification. I'm not a Vertica expert but I find taking certification exams helps you also understand your shortcomings of a product. For instance, I passed my SNIA (SAN) certification on the first try with a perfect score. However, this was just dumb luck. Every question on NAS and tape storage I guessed at, and the right answers were fairly obvious. Since I'm not a full-time SAN guy, I'm a data professional, I don't have much need for tape and NAS so I really didn't care to learn more about those topics. But it was interesting learning what SNIA feels is important in the storage world.
I've been using HP Vertica since before HP bought the company. I first wrote about Vertica in 2010 when I wrote about column-oriented databases. I'm again using Vertica in my daily responsibilities and I decided to try to get my Vertica certification. I'm not a Vertica expert but I find taking certification exams helps you also understand your shortcomings of a product. For instance, I passed my SNIA (SAN) certification on the first try with a perfect score. However, this was just dumb luck. Every question on NAS and tape storage I guessed at, and the right answers were fairly obvious. Since I'm not a full-time SAN guy, I'm a data professional, I don't have much need for tape and NAS so I really didn't care to learn more about those topics. But it was interesting learning what SNIA feels is important in the storage world.
In the process of getting my Vertica certification I thought it would be wise to put together a blog series on Vertica for anyone else that wants to learn this technology rapidly in a hands-on fashion. In these blog posts I'll cover what Vertica is, how to install it, we'll migrate AdventureWorks to it, and we'll do lots of fun labs along the way. The posts will be geared toward those data folks who are familiar with MS SQL Server. I specifically approach learning Vertica by calling out its differences with SQL Server.
You'll find this is a lot of fun. Vertica is pretty cool.
Briefly, what is HP Vertica?
It is a column-oriented, compressed, relational DBMS. Many people consider this a NoSQL solution, but it does use a dialect of SQL for its manipulations. It is clustered across grids and nodes like many distributed NoSQL solutions, with builtin data redundancy (called k-safety), which 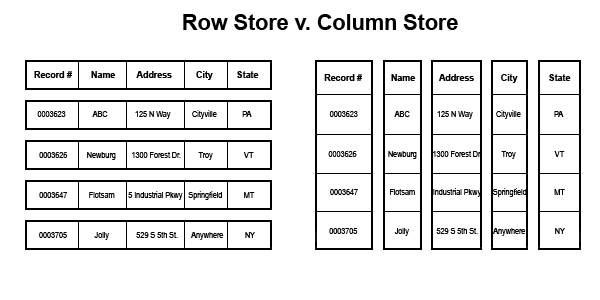 means it has the typical marketing gimmick of "requiring no DBAs". I can assure you that it performs QUITE NICELY for read-intensive workloads. There is also an entire analytics platform that comes with Vertica...roughly equivalent to SSAS.
means it has the typical marketing gimmick of "requiring no DBAs". I can assure you that it performs QUITE NICELY for read-intensive workloads. There is also an entire analytics platform that comes with Vertica...roughly equivalent to SSAS.
What makes Vertica unique is that it persists the data in groupings based on the column of the tuple (table) instead of row-oriented, traditional, RDBMS offerings. If you think of a table as a spreadsheet then retrieving a single row is an ISAM-type of operation. This works very well for OLTP applications. But in some reporting applications it is possible that you care more about an entire column than about the individual rows. If your query is something like "give me the total sales for this year" then querying a columnstore will result in far less IO and will run radically faster.
Even the amount of utilized disk to store the data will be less. Columstores compress much better because like data types are grouped together. Basically, there are more rows than columns and each row will need "offset" information to store the different datatypes together. You'll need fewer offset markers if you organize your storage by column. TANSTAAFL (there ain't no such thing as a free lunch), as economists say...the cost is that updates to existing rows require one write per column in the table. So a columnstore is probably not best for your OLTP tables.
That's a quick overview and is not all-inclusive. I'll cover lots more in the next few posts.
What's it cost?
The Community Edition is free for up to 1TB of data. And if you consider that compressed columnstores generally take up a fraction of the space of a traditional row-oriented DBMS...that's actually a lot of data.
HP Vertica Documentation
Vertica documentation in HTML and PDF format
Getting Started
You need to register with HP to be able to download the Community Edition. You can do this at my.vertica.com. After you register you'll immediately be able to download the CE (or the drivers, Management Console, VMs, AWS documentation, etc).
In the next post I'll cover how to install Vertica on Ubuntu. You can of course download a VM instead but I believe the best way to learn a product is to start by actually installing the bits.
You have just read [[HP Vertica]] on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
nosql data architecture vertica