
DevOps: The Ways
This post in my DevOps series will cover "The Ways".
You'll almost never hear The Ways mentioned with DevOps. That's ashame because when you hit the Third Way, then DevOps is working for you...your development and operations teams are thinking as one. The Ways is often associated with Kanban. The Ways sounds like some kind of Kool-Aid cult blathering, but if you understand it, it works.

(in this case it should be cleear that the bottleneck is the middle column...whatever that is) |
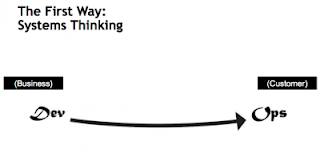
The First Way is the visual management of work and pulling work through the system. A good Kanban board can do this. We want to see the fast flow of work through the system. An outsider can look at it and immediately see where the bottlenecks are in your process without any prior knowledge of your business or Kanban. If your Kanban board isn't doing this then you need to study Kanban some more. You can think of the First Way as "systems thinking". How do we get work out the door? It's kind of very waterfallish. Things move from left to right. At this phase of DevOps there is still clear delineation between the developers and the Ops guys. In this phase the bottlenecks tend to be after development and generally falls with the Ops guys. This is because we still have developers who are rolling out code without much thought as to how it will be operationalized and who will support it.
The Second Way is to make waittimes visible. You need to know when the work takes days sitting in someone's queue. This may not necessarily be a bad thing but it should lead you to ask some difficult questions. Do we have enough resources at that phase? Are those resources being utilized at the right "workstation"? Or is that resource getting pulled in too many directions. When your manager complains that it takes too long to do a certain task, perhaps it is due to waittimes?
 The Second Way is sometimes thought of as moving DevOps into the "feedback loop" phase. The Ops guys should be providing feedback to the devs regarding what worked and what didn't so that the next release is smoother and there are fewer bottlenecks. In other words, your "DevOps maturity" is improving at this phase and DevOps should begin to show you dividends.
The Second Way is sometimes thought of as moving DevOps into the "feedback loop" phase. The Ops guys should be providing feedback to the devs regarding what worked and what didn't so that the next release is smoother and there are fewer bottlenecks. In other words, your "DevOps maturity" is improving at this phase and DevOps should begin to show you dividends.
I like my definition of the Second Way better (make waittimes visible). In larger organizations where inertia makes dev and ops collaboration politically impossible it is better to think of the Second Way as figuring out what is wrong with the First Way. Queuing Theory is very concerned with understanding why service times are long and generally you'll find the biggest culprit is waiting on some unavailable resource. This holds equally true whether you are examining the performance of a SQL Server that is waiting on IO subsystems or development teams waiting on QA resources.
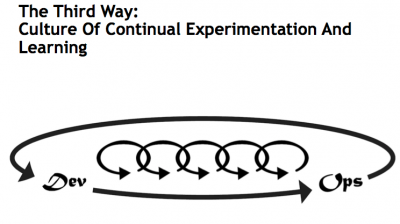 The Third Way is to ensure that we are continually putting tension into the system, so that we are continually reinforcing habits and improving something. It doesn't matter what you improve, as long as something is being improved. If you are not improving then entropy guarantees that your competitors will beat you. I've heard IT people tout this as the equivalent of simple DR fire drills. I think that is too simplistic. The fact is, a DR fire drill tends to involve only Ops guys. I don't know too many developers getting involved in these. And remember that DevOps is NOT a simple melding of your developers and Ops guys. It is collaboration, not job redefining.
The Third Way is to ensure that we are continually putting tension into the system, so that we are continually reinforcing habits and improving something. It doesn't matter what you improve, as long as something is being improved. If you are not improving then entropy guarantees that your competitors will beat you. I've heard IT people tout this as the equivalent of simple DR fire drills. I think that is too simplistic. The fact is, a DR fire drill tends to involve only Ops guys. I don't know too many developers getting involved in these. And remember that DevOps is NOT a simple melding of your developers and Ops guys. It is collaboration, not job redefining.
You'll know when you are ready for the Third Way when your people start to get bored. That means they understand DevOps and Kanban and are not being challenged by it anymore. Here's a simple way to move into the Third Way. When you see entropy set in then make an announcement that some simple feature request will be handled as though it were a P0 ops emergency. The request will be fast-tracked through the system to see how long it takes to move a request from a BA through to operationalization. It may take 5 days. Wait a few weeks and take a similarly-scoped request and repeat. See if you can get your team to reduce the cycle time to 3 days. Then figure out what the bottlenecks were that you removed.
Summary
There is so much that can be written about The Ways. To be succinct, think of your IT team as working on a factory floor and you as the manager are overseeing the activity from the catwalk. You want to see no bottlenecks, no unplanned work, and no excessive waittimes as the work moves along toward doneness. Then you want to introduce a defect and watch the floor workers swarm to fix the flow of work through the system. When the defect has been resolved the factory floor should return to its previous state. Granted, for an IT manager or scrum master it is difficult to think of your IT staff as factory workers, but this method does work when you really need to determine who and what is your bottleneck.
You have just read "DevOps: The Ways" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
devops