
Couchbase Notes
If you have 10 minutes this blog post will give you a quick overview of what Couchbase is, how it works, and some gotchas. Couchbase is a document-oriented, key-value store that is very simplistic. But it's also rock solid. If you are evaluating document stores and you need to come up to speed quickly on Couchbase then this post is for you.
This post is meant as a quick 10 minute guide Couchbase. This will be helpful if you are evaluating NoSQL document stores or if you need a quick primer on Couchbase so you can do some rudimentary administration, quickly.
Couchbase (referred to as cb for brevity for the remainder of this post) is a document-oriented, schema-less database that is a superset of the basic key/value structure of memcached. If you already use memcached then cb is even more compelling.
Terms
- document ID: the "key" of a bucket. It must be unique. Can be any string or datatype you want. Even a URN. A UUID/GUID can be generated from your application library, couchbase doesn't provide one.
- Buckets: logical groupings of data, roughly equivalent to a schema or database. 2 types:
- couchbase: standard. Provides replication and disk-backing. Survive node failures and cluster reconfiguration while continuing to service requests. Bucket sizing is fluid. Different sockets/ports can access different buckets. Documents exist until deleted or expired based on an expiry that is set on the document.
- memcached: in-memory document cache. 100% API compatible with couchbase buckets. Documents persist until deleted, expired, or until the couchbase service stops.
- vBuckets: subsets of buckets holding key ranges. A given node is responsible for its vBucket key ranges. vBuckets are replicated to other nodes but only one node at a time is responsible for a given vBucket's keyspace. You don't declare vBuckets, couchbase does this for you.
- Cluster: groupings of nodes housing the same buckets of data, but not necessarily complete copies of the entire bucket. Clients communicate directly with the node housing the data, yet the client doesn't need to maintain the list of servers like memcached. This is all accomplished with vBuckets. Every documentID belongs to a vBucket and a mapping function determines which server(s) has that vBucket shard.

An example of couchbase UI. This cluster has 6 buckets. The graph shows you have many query operations are performed per second, and out of those, how many were served from disk. If performance is your goal, and with couchbase it should be, then you want as many requests served from RAM as possible.
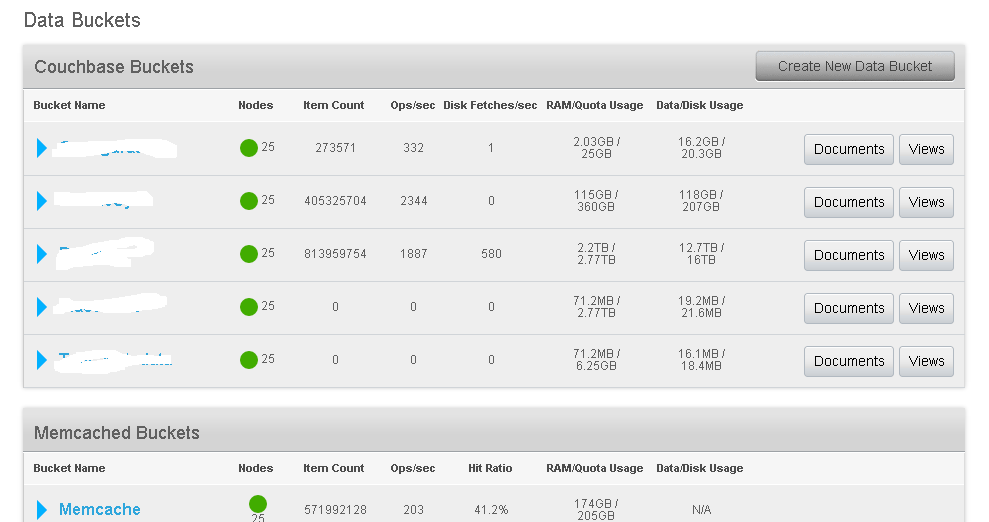
CouchbaseUI shows you a listing of buckets by "type"...native, disk-backed buckets and memcached buckets, which will not survive a couchbase cluster restart. This isn't a huge issue if you have a proper replication factor and enough nodes in your cluster. Couchbase is rock-solid.
Key Features
- tries to retain as much of your actively used data in memory at all times. So, when choosing disks, consider SSDs over network-mounted storage.
- sub-millisecond/high concurrency access
- shared-nothing. Every node is an equal peer with every other node. There is no hierarchy to the nodes or a "master" node. Each node has the cluster management software and the UI.
- Scalealbed. Just add more nodes as needed. Just install the software on another node and add it to the existing cluster.
- Data is replicated. Each node is responsible for its data, but that data is also replicated to other nodes in the cluster.
Some Possible Shortcomings
- Rebalancing a cluster can take a very long time depending on the size of the buckets (data sets) and the number of nodes. Basically vBuckets need to be redistributed to the other nodes and all nodes need their pointers updated. The cluster remains running and servicing requests during this time.
- Removing, adding, and failing over nodes can also take a long time due to the architecture.
- Does not provide a rich query language. Or any query language. You retrieve, save, remove, and update documents by the "document id". There is no good way to query by "values"
Administration
is performed via the couchbase UI which is available on a given port by connecting to any single node.
An example of couchbase UI. In this example the cluster has about 6TB of data and shows how much is cached in RAM.
- REST API is also available
- CLI is also available. Every tool uses the REST API under-the-covers.
- regular maintenance of your cluster and nodes really isn't needed. It is very much self-managing.
- Very few configuration variables that you can set.
Backups
cbbackupis the tool used to make backups- backups exist at the bucket level, nothing more granular
- backups can be restored to the same cluster or a different cluster. Even if the cluster has differing numbers of nodes the restore will still work
- the cluster topology is not saved in the backup format so you can restore to smaller or larger clusters, nodes with different names, etc.
- backups can have a deleterious effect on performance since data that is not in cache needs to be brought to cache during the backup process. This means that important cached data may get aged out of memory. Many people use the Tap Library to do backups instead using custom code. The Tap Library avoids the disk-to-memory transfer and means that backups can be streamed to alternate storage locations.
- dbrestore is the tool used to restore cb buckets. Can restore to the same nodes, a new cluster with a different topology, etc.
Replcation/Failover
- Always remove a node rather than fail it over, when possible. This ensures no data loss, otherwise there are edge cases where documents can be lost if they are not-yet replicated.
- Peer-to-peer based replication is used to copy data to other nodes for HA purposes. There is no master/slave relationship. You can configure replicas on a per-bucket basis to support your desired safety levels. But this cannot be changed after the bucket has been created. Best to start your couchbase installation with at least 3 nodes so you can have a relatively safe replication scheme for the future.
- A failover merely activates a replica to be "authoritative" for those vBuckets. Automatic failover is off by default. An external monitoring system should be used to ensure failover happens for the right reasons. Even if automatic failover is enabled it won't be activated if two or more nodes go down since this could be disastrous and may be indicative of issues somewhere else in the data center. Automatic failover will only occur for a single node before administrator intervention is required to reset the auto-failover counter. Automatic failover only occurs after a node is down for 30 seconds.
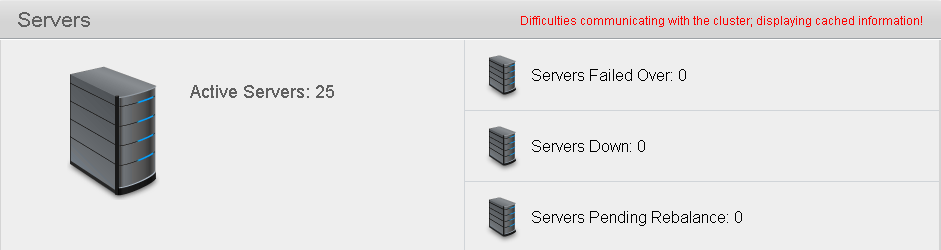
CouchbaseUI shows you the number of nodes in your cluster, how many are down or failed over successfully, as well as how many nodes are participating in a rebalance because the cluster size has changed. Rebalances can take days if your couchbase buckets are large. Therefore cluster-wide operations such as upgrading couchbase, can take weeks. However, during all of these operations the cluster is still servicing requests with negligible impact to performance.
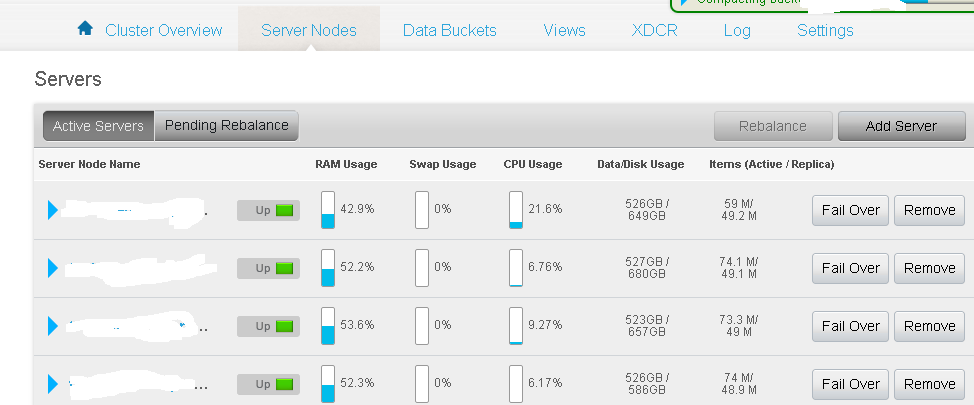
This screen shows a list of nodes and statuses. This is also where you can add additional nodes, with the couchbase binaries installed, to your cluster.
Connectivity
- memcached clients can connect to couchbase without code modification. couchbase is a drop-in binary replacement in this scenario. This is accomplished using the Moxi proxy service.
- Moxi can be installed on the couchbase servers or on the client.
- The client is the recommended deployment solution since it avoids an extra network hop.
- The clients know which nodes contain which document IDs and therefore where to call if Moxi is running on the client.
- Smart clients, however, which are written specifically for couchbase and do not require Moxi, are the preferred connectivity solution if backward-compatibility with memcached is not a requirement.
- Smart clients are available that can talk to the couchbase cluster and handle failover and replica querying.
Querying
- queries are always by documentID. Querying by value is not handled in a performant manner. So code always looks something like this:
client = Couchbase.new "http://localhost:8091/pools/default"
something = client.get "mynamespace.key"
- Queries any more complicated than that are highly discouraged and will not be nearly as performant.
- You can query for multiple document IDs in bulk, as long as you know the document IDs you need.
- There is no way to query a bucket for a list of used ids or any other kind of lookup. The only lookup is by id. This isn't necessarily a problem if you take this architectural decision into your application design. For instance, lookups can be done if you design and code linked lists in other documents.
- If you need a document store with richer query facilities consider redis.
- The query facilities are getting better in Couchbase 2.0. If you use JSON then couchbase will offer indexes based on the keys in your documents.
Document Structure
- Since all data access is by key and never by value, cb is truly schema-less. Every document can have its own unique structure.
- The document's data is just a stream of bytes, you can use anything you want to "structure" it. Most times you'll want to use something like JSON.
- Generally the client library you use will provide a serialization/deserialization mechanism to do this for you.
- JSON is not required, if you solely use Java then you could use Java's serialization/deserialization mechanisms which will give you a simple string.
CRUD Architecture
- There are no write operations on multiple documents (similar to an UPDATE statement without a WHERE clause in an RDBMS). All set operations much be passed a singleton key.
- Documents have an expiry flag.
touch()andgetAndTouch()will update the expiry. - There is no locking because the set operation is always atomic. But that means when there are concurrent set operations that the last one will always win.
- concurrency, if required, is handled by the cas() function
- check and set
- builds a hash for the document and then compares it when the set is issued to ensure no one has updated the document since it was read.
- You can write your own code to manage the concurrency differently, including race conditions.
You have just read "[[Couchbase Notes]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed.

Dave Wentzel CONTENT
nosql