
Continuous Integration Testing with MD3
Over the last several posts I've covered [[Introduction to Metadata Driven Database Deployments|MD3]], my database deployment utility for SQL Server-based applications. MD3 handles stateful database object  deployments. In those posts I've constantly mentioned that one of the benefits of a using a declarative database deployment utility is the ability to create proper "CI build loops". In this post we're going to finally see how to do this. Even if you don't use MD3 I'll show you the right way to setup your CIT testing (continuous integration testing). MD3 makes CIT ridiculously easy and includes the necessary scripts to make CIT a reality, quickly.
deployments. In those posts I've constantly mentioned that one of the benefits of a using a declarative database deployment utility is the ability to create proper "CI build loops". In this post we're going to finally see how to do this. Even if you don't use MD3 I'll show you the right way to setup your CIT testing (continuous integration testing). MD3 makes CIT ridiculously easy and includes the necessary scripts to make CIT a reality, quickly.
What is Continous Integration Testing?
Continuous integration testing (referred to as CIT for the remainder of this post) is the process of checking in (or merging) your code daily and setting up a mechanism to ensure the code actually compiles. Most shops also run a series of unit tests after the compile to ensure the application functions as designed. This is one part of a philosophy known as "test driven development". If there are build breaks then most shops have a "stop the line" mentality where everyone stops their current work to fix whatever is broken in the build. The theory is that the longer we allow broken builds then the more risk we introduce as features cannot be tested soon after they are developed. Broken builds beget broken builds. None of this is controversial and is a standard practice in the software development industry.
Except when it comes to databases. Very few shops have proper database CIT in place, if any. Similarly, very few shops have any database unit testing either. There are some good reasons for this, the biggest reason is something I've mentioned numerous times in these posts...databases have "state" and it is difficult to account for state when building a database deployment tool, let alone dealing with unit testing and automated deployments.
Most technology folks simply don't know how to test their database scripts in an automated fashion. Further, most guys don't even know what to test.
Before we get into the details of CIT we should first determine just how complicated your CIT needs will be. We do that by determining how many "releases" of your database/application you must support.
How many "releases" of your database do you support?
There are two choices:
| Type | Description | Examples | CIT Complexity | Versions You Support | Level of Support for Previous Versions |
|---|---|---|---|---|---|
| Type1 | You support one production database and ultimately deploy all scripts to that database. |
| Very simple | One (the current production) | Zero (not needed). Once you deploy Version Y to prod your support for Version X ends. |
| Type2 | You support many customers, each with different releases/versions of your database/application |
| Complex | More than one | The more versions you support the more complex CIT becomes |
You know your database is a "Type1" database if the ultimate target of your database deployments is one, single production database. Your application is still Type1 even if you have multiple customers but only one multi-tenant database. In this scenario when you upgrade your database/application then all customers are simultaneously on the new release. If you support multiple production versions of your database, usually because you are an ISV, then you are a "Type2" database. We'll see why this matters soon.
The basic requirements of database deployment testing
Regardless of whether you are a Type1 or Type2 database there are some basic requirements for CIT. This is why we build CI Loops:
| Test Name | Requirement | Description | How to do it |
|---|---|---|---|
| Compile Test | Ensure all scripts compile and execute without error | We want to catch cases where someone accidentally checks in code like this: CREATE TALBE dbo.Employees. This will generate a syntax error and will break the deployment. |
|
| F5 F5 Test | Ensure scripts don't fail on subsequent deployments. | In this case the script will run properly the first time, but will fail on subsequent deployments. We call this the "F5 F5" test because it simulates running the script twice in SSMS (by pressing F5 twice). | Deploy your database scripts again to |
| Net New vs Upgrade Test | Ensures upgraded databases are identical to net new databases | We want to ensure that our upgraded databases have the same schema and model data as our net new databases. If there are differences then we know we have something wrong with our database scripts. | After deploying to NetNew above we deploy to a database from our previous release(s) and then compare the results. This could also be our prod db or a customer db. |
On top of this, after each deployment we should rerun our database unit tests, if they exist. I totally recommend TSQLT for this.
What are the "differences" we are testing for
In the table above I mention many times that we are checking for "differences" between two databases. Specifically we are looking for schema and model data differences. In the MD3Objects\Validators folder we provide you with two procedures that help to do this, MD3.CompareSchemas and MD3.CompareMasterData.
MD3.CompareSchemas
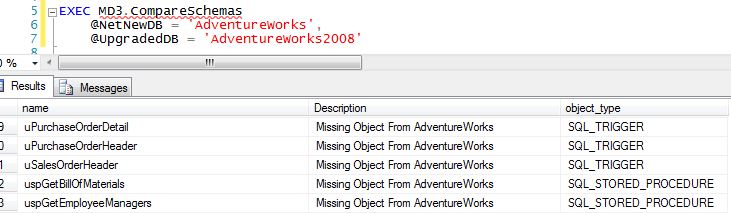 MD3.CompareSchemas: is a stored procedure that compares the schema of two databases and notes any differences. It looks specifically for:
MD3.CompareSchemas: is a stored procedure that compares the schema of two databases and notes any differences. It looks specifically for:
- missing/different table columns
- missing objects (triggers, views, constraints)
- index differences
Any differences that are reported may indicate a problem with your database deployment scripts. In the screenshot to the right I compare two versions of the AdventureWorks db and report on the differences. Note in the screenshot that we are missing some stored procedures and triggers, indicating that something is wrong with our deployment. MD3.CompareSchemas is a great utility for comparing the schemas of any two databases, not just testing that your deployment scripts are working as designed.
MD3.CompareMasterData
MD3.CompareMasterData compares table data between two databases. First you need to define which tables should be part of your comparison. This 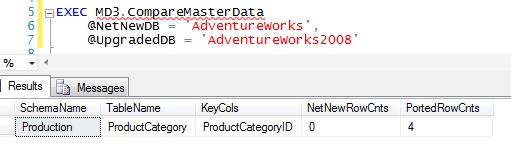 would include your model data tables (I discussed this in the post [[MD3 Model Data Patterns]]). The first check is a simple rowcount check. It then looks for data differences by checking the
would include your model data tables (I discussed this in the post [[MD3 Model Data Patterns]]). The first check is a simple rowcount check. It then looks for data differences by checking the bin_checksum against the keys of the table. Not only will this show you the model data differences between a net new and upgraded database, but you can run it against a previous release of your database to see what model data has changed in this release.
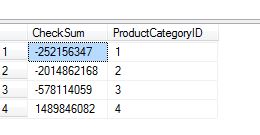
The graphic to the right shows that the model data rowcounts are wrong between my net new and upgraded db. My net new db is missing all of its model data for Production.ProductCategory. In the graphic below we see what happens when the "data" for the non-key columns in Production.ProductCategory differ. In this case the bin_checksum does not match and that is reported for a developer to check.
The "hows" of CIT
Hopefully you understand what you should be testing with your database CIT process. Now we get into how to do it. I have not included any "CIT scripts" with MD3 because it is heavily based on your requirements...is your db a Type1 (one prod database/one version supported) or Type2 (ISV with many prod databases at different versions) database? Also, every shop uses a different CI tool. I prefer Jenkins but TeamCity is also excellent. You could just write a simple PoSh script that kicks off the necessary tests and sends out notifications of build breaks. Let's just cover the basics of how you do CIT with your database.
For every active code branch of your source code you should have the following tests:
| Test Name | Purpose | Process | Test Assertions |
|---|---|---|---|
| Compile Test | Ensure all scripts compile and execute without error |
|
|
| F5 F5 Test | Ensure scripts don't fail on subsequent deployments. |
|
|
| Upgrade Test | Ensures upgraded databases are identical to net new databases |
|
|
In the Upgrade Test I said that you will run this test on at least one copy of a production database for every release you support. This is only necessary if you support a Type2 database (you are an ISV). Let's assume you are currently developing and testing Version 4 of your application and you have customers on Version 1, 2, and 3. In this case you want to obtain representative databases for each of those releases for CIT testing. Copies of customer databases work the best, but older non-prod copies work as well. The goal is to ensure that our database scripts are written to ensure that the oldest databases we support can be upgraded without error.
This becomes a lot of CIT processes that need to be setup. In the case where you are developing for Version 4 we actually need to perform 5 separate database deployments:
- Compile Test
- F5 F5 Test
- Version 1 Upgrade Test
- Version 2 Upgrade Test
- Version 3 Upgrade Test
And that is only for your Version 4 code branch. If you have other branches that you maintain then you should have tests for each of those branches as well.
Now let's assume that with Version 6 you cease support for Versions 1 and 2. In that case your CIT process looks like this:
- Compile Test
- F5 F5 Test
- Version 3 Upgrade Test
- Version 4 Upgrade Test
- Version 5 Upgrade Test
Your CIT process will be the most valuable when your Upgrade Tests are using representative databases. If you are just going to run CIT against old dev databases you probably will miss a few issues. You'll get better results using a perf or QA environment from those older releases. But you'll get the best results if you use actual customer databases to test your upgrades. I've worked for ISVs with severe data privacy rules and we were still able to get "scrubbed" copies of their prod databases. If you can get actual databases then you are almost guaranteed that a prod database deployment will never fail since you are running CIT often...maybe even after every code checkin. Further, you can measure the approximate duration of the deployment which will show you how much downtime is required.
When to run the CIT Build Loops
You should really use a tool like Jenkins or TeamCity that monitors your source code repository and starts another round of CIT whenever a new checkin occurs. However, that's potentially a lot of tests that need to be run multiple times per day. In that case maybe you only want to run the Compile and F5 F5 tests on every checkin, then run the full suite of tests once per day. It's entirely your call. The more you run the CIT loops the sooner you will spot problems.
Summary
In this post I covered how I like to do database CIT. Your needs may be different depending on how many releases of your prod database(s) you support. But the concepts are similar. You want to ensure your code runs correctly, then reruns subsequent times without side-effects. Those side-effects are errors, schema differences, and differences in model data. The better your CIT process the more reliable your final production deployments will become. If you work in a shop where a prod deployment causes you sleepless nights then implementing a good CIT will alleviate that.
In [[MD3 Extensibility Stories]] I'll cover how I used this CIT process to get our deployments to under 7 minutes for a huge OLTP system. I'll also show how using CIT with MD3 saved us thousands of man-hours.
You have just read "[[Continuous Integration Testing with MD3]]" on davewentzel.com. If you found this useful please feel free to subscribe to the RSS feed. 
Dave Wentzel CONTENT
md3 data architecture sql server