
Apache Flume
 During my evaluation of NoSQL solutions the biggest hurdles I had, by far, was loading data into Hadoop. The easiest way I found to do this was using Apache Flume. But it took me a long time to figure out that my approach to data loading was wrong. As a RDBMS data architect I was biased towards using techniques to load Hadoop that I would use to load a SQL Server. I tried scripting (which is how most of the NoSQL solutions have you load their sample data, but tends not to work well with your "real" data) first but the learning curve was too high for a proof-of-concept. I then tried using ETL tools like Informatica and had better success, but it was still too cumbersome.
During my evaluation of NoSQL solutions the biggest hurdles I had, by far, was loading data into Hadoop. The easiest way I found to do this was using Apache Flume. But it took me a long time to figure out that my approach to data loading was wrong. As a RDBMS data architect I was biased towards using techniques to load Hadoop that I would use to load a SQL Server. I tried scripting (which is how most of the NoSQL solutions have you load their sample data, but tends not to work well with your "real" data) first but the learning curve was too high for a proof-of-concept. I then tried using ETL tools like Informatica and had better success, but it was still too cumbersome.
I began thinking like a NoSQL Guy and decided to use HiveQL. I had better success getting the data in to Hadoop...but now I had to get the data out of my RDBMS in a NoSQL-optimized format that I could quickly use HiveQL against.
As my journey continued I thought about how I would intend to get my data into Hadoop if we ever deployed it as a real RDBMS complement. We would probably write something that "listened" for "interesting" data on the production system and then put it into Hadoop. That listener is Apache Flume. Why not just point Flume to listen in to our Service Broker events and scrape the data that way. I had that up and running in a few hours.
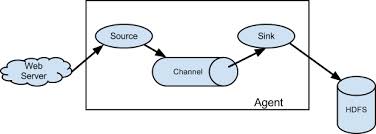 Flume works by having an agent running on a JVM listen for events (such as Service Broker messages to a JMS system). The events are queued up into a "Channel". The channels produce new outgoing events to Hadoop/HDFS/HBase (or whatever you use for persistence). So, why use a channel in the middle? Flexibility and asynchronicity. The channels have disaster recovery mechanisms built in. As your throughput needs change you can configure your agents to do fan-in (more agents talk to fewer channels) or fan-out (less agents talk to more channels). The former is great if you have, for instance, multiple listeners that only need to talk to one Hadoop instance. The latter is good if you have one source system that you want to talk to multiple Hadoop instances. Or if you need to route messages to a standby channel to do maintenance on your Hadoop instance.
Flume works by having an agent running on a JVM listen for events (such as Service Broker messages to a JMS system). The events are queued up into a "Channel". The channels produce new outgoing events to Hadoop/HDFS/HBase (or whatever you use for persistence). So, why use a channel in the middle? Flexibility and asynchronicity. The channels have disaster recovery mechanisms built in. As your throughput needs change you can configure your agents to do fan-in (more agents talk to fewer channels) or fan-out (less agents talk to more channels). The former is great if you have, for instance, multiple listeners that only need to talk to one Hadoop instance. The latter is good if you have one source system that you want to talk to multiple Hadoop instances. Or if you need to route messages to a standby channel to do maintenance on your Hadoop instance.
This means that Flume is very scalable and can handle constant data streams effectively without worry of data loss. This is great for something like streaming stock quotes. Flume is by far the easiest way to load data quickly into Hadoop.
Dave Wentzel CONTENT
data architecture service broker nosql