
ALTER SCHEMA TRANSFER for Zero Downtime Database Upgrades
Our software has a Zero Downtime requirement for database upgrades. In the past it took us hours to upgrade our databases from one release of our software to the next. After doing some basic process-improvement stuff (like taking log backups instead of full backups after taking the system down) we next worked on making sure our index changes were able to utilize the ONLINE=ON option. We could even refactor/change the normalization of tables and keep the data in sync using triggers and Service Broker. There were a few things we just couldn't seem to do while the application was online. This blog post is how, I think, you can perform just about ANY database refactoring while your application is online. Without incurring a noticeable performance penalty or affecting concurrency.
But first, some background. Our software/database is deployed at about 50 customers, ranging in size from ~100GB to 13TB. Each customer can be, unfortunately, on a different version of the software at any point in time, and some customers even run multiple versions of the software. The database must be upgradeable from any version to the "current". The software and databases can be hosted at the customer site or in our own "cloud". I've written in the past about how to we reduced downtime when migrating from SQL 2005 to SQL 2008. I also wrote about my database porting process numerous times and how it handles upgrading any version of any database to the "current" build. Here specifically I compare and contrast it with Data Tier Applications. All of these things get us "reduced" downtime, but not "zero" downtime. I did a write-up a number of years ago about a [[Zero Downtime Initiative Skunkworks Project|skunkworks project]] I led where we tried to get to the elusive "zero" downtime.
Using the method I'm about to outline we finally got to "zero" downtime. Quick definition of "zero"...it's actually not "zero" downtime, it's "near-zero". We actually require our application and database to be quiesced for about 10 seconds while we "true-up" the system and make the switch. In theory we could use this technique for total zero downtime database upgrades if we spent a little more time on "rolling upgrades" of our Java tier, but the cost outweighed the benefits. It turns out 10 seconds (or so) of downtime was a good enough requirement.
Darwin
On to the approach. We decided to call this process "Darwin" since it takes the current database and "evolves" it under the covers. I am a firm believer in [[DeveloperArchitect Topics|evolutionary database design]]. The Darwin approach is to:
- Use a separate "Stage" schema to create your n+1 release database code changes.
- Use a mechanism such as replication, triggers, or Service Broker to keep the data synchronized if a table's schema is changing.
- Do a "check-out" of some kind to ensure that Darwin is in-place correctly and data is "evolving".
- When you are ready to switch over simply turn off your data synchronization mechanism and issue ALTER SCHEMA TRANSFER commands to transfer out the old versions of your code to a "Deprecated" schema and then transfer your "Stage" schema to your production schemas. The ALTER SCHEMA TRANSFER is a near-instantaneous metadata operation.
- Rerun your permission (GRANT) scripts. These are the only objects that are not carried-forward with ALTER SCHEMA TRANSFER.
- If anything goes wrong run the reverse ALTER SCHEMA TRANSFER commands and your system is totally reverted without having to resort to a database RESTORE.
Real World Example
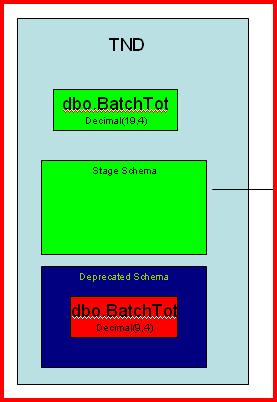
For the example I show next we will assume that our production schema is "dbo" and our data synchronization mechanism is simple transactional replication. The problem is we have a table called dbo.BatchTot that has a series of columns that hold monetary data that are defined as decimal(9,4). The requirements have changed and now those columns must be declared as decimal(19,4). The table holds ~2 billion rows at our largest customer.
If you attempt to run a command like "ALTER TABLE dbo.BatchTot ALTER COLUMN Blah decimal(19,4) NOT NULL" where Blah is currently a decimal(9,4), a "size of data" operation occurs and the ENTIRE table must be rewritten to accommodate the increase in disk size required for the new datatype. While that occurs the table is serialized (Sch-M locks) and potentially you risk running out of tran log space.
Many of our architects proposed using what I call the "deprecation model" to accomplish this. In essence:
- we add new cols (called BlahNEW for instance) to hold the values from the original columns
- put a trigger on the table to keep the cols in sync
- write a little SQL that will cause every row to be "updated" and fire the trigger.
- Change all code to use the BlahNEW cols.
- Drop the Blah cols
I hate the deprecation model because it requires you to change all of your references from Blah to BlahNEW (the red highlights above). In a large application this is really hard to test. But the real issue is a "people" problem. As deadlines slip we of course decide that we can reduce testing to maintain project deadlines. That's a mistake. Or we decide that there is no time to write the code that drops the old cols, so they stay there forever, along with the deprecation code in the Java tier.
It's just a bad pattern in my opinion.
So we decided to use Darwin.
Pre-Downtime
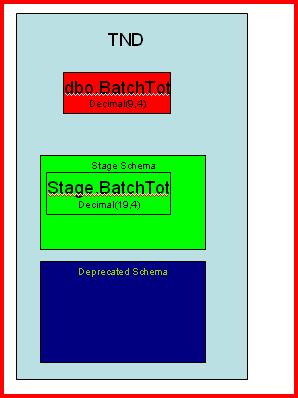
These steps run while the system is up. They are not impactful to online users. First, we create our Stage and Deprecated schemas. Stage is where our new objects will go. Deprecated is where the old dbo objects will be placed when we switch over to the new version of the software.
 |  |
Now we will create all of our n+1 version objects in the database. Remember, these are applied to the Stage schema. For simplicity I really just care about BatchTot and the new length of my columns.
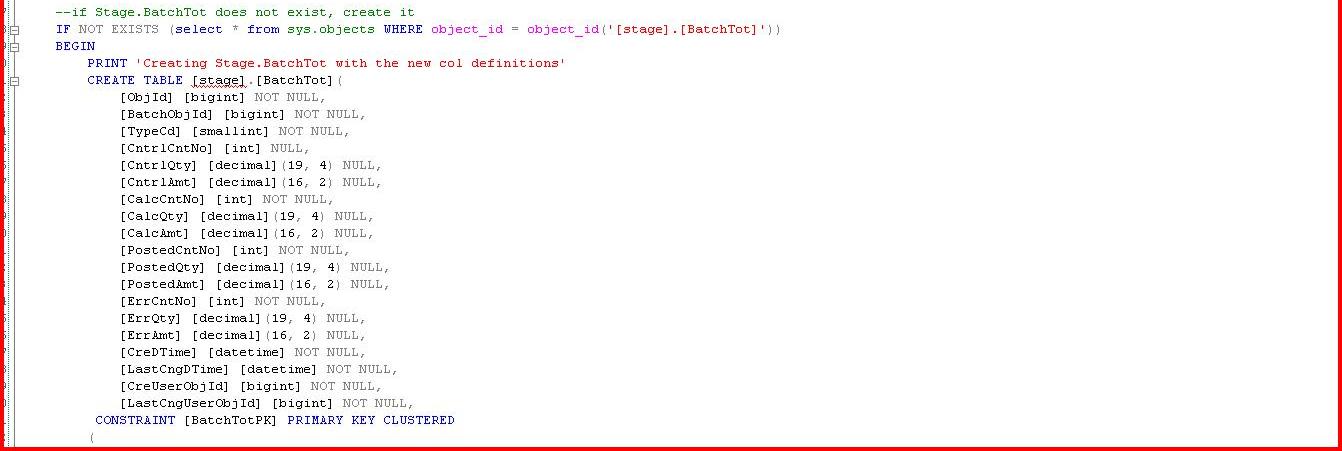 |
|
Now we need a mechanism to keep the data synchronized. My choice for this is transactional replication. So we create a new publication with an article of dbo.BatchTot. The subscriber is the same database. The destination is simply Stage.BatchTot. The sync_type should be 'database snapshot' so that snapshotting the table will hold the shortest-duration locks on dbo.BatchTot as possible. Once replication is synchronized you can do a "check-out" of your new application if desired. You are done with the pre-downtime steps. The beauty is that if anything goes wrong we have not impacted our production users of the current version of our software. Replication is only a slight performance penalty, but you should of course determine what is best for your needs. | 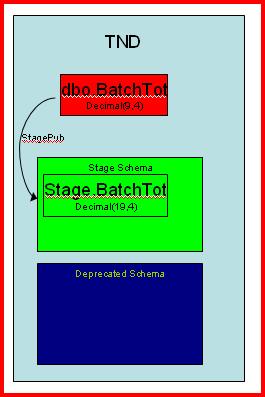 |
Downtime
When you are ready for your downtime you simply need to quiesce your system. This means that you have no active transactions and distribution agents are completed. We are "truing-up" the system.
Now we run two ALTER SCHEMA TRANSFER commands. The first moves the current version objects to the Deprecated schema from dbo. The second moves the Stage schema objects to dbo. This process moves all "dependent" objects as well to the destination schema. By "dependent" I mean any indexes, constraints, and keys. It does not, however, move permissions. Those are "lost" during the transfer, so you simply need to reapply them. I would assume this is a conscious decision by Microsoft to ensure we don't introduce any gaping security holes.
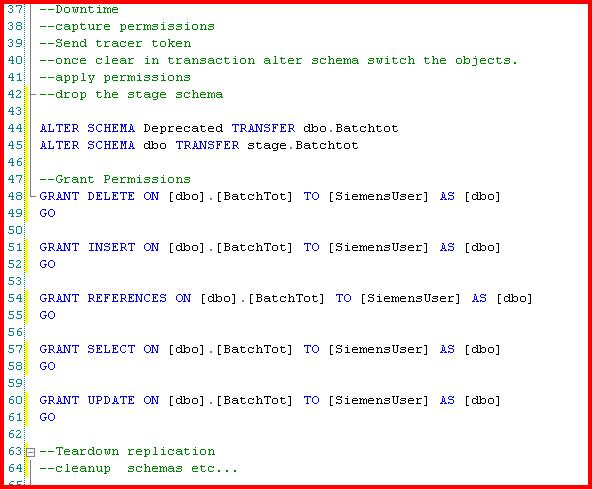 |  |
As mentioned above we now also need to teardown replication.
Next Steps
You can also remove the Deprecated and Stage schemas whenever it is convenient. I usually keep them around "just in case" for a few days.
The ALTER SCHEMA TRANSFER process never seems to take us longer than 7 seconds, even for large tables or Stage schemas with many objects. I assume under-the-covers that Microsoft has implemented this as a "metadata-only" operation.
Summary
I have only scratched the surface of what can be done with "Darwin" and ALTER SCHEMA TRANSFER. I believe this is an extremely simple method to get to near-zero downtime database upgrades. It is not as costly as Oracle's GoldenGate and is conceptually simple to understand for most people. It even has a built-in "rollback" mechanism. I hope this blog post was interesting and helps you in the future.
Dave Wentzel CONTENT
sql server data architecture