
Performant ETL and SSIS Patterns
It's a helluva job market out there right now if you have ETL, SSIS, DataStage, or equivalent experience. I guess you can make some generalized deductions about this:
- more companies are trying to integrate their data stores.
- more companies need to copy data from OLTP to OLAP systems.
- It's hard to find good ETL people.
 Unfortunately, too many job postings ask candidates to have specific ETL tooling experience such as SSIS or DataStage. This is unfortunate. Too many candidates have great tooling experience but have very little grounding in ETL best practices, regardless of chosen tool. I've been called in a lot lately to help fix various ETL processes. Each one is using a different ETL tool and each one is exhibiting the same terrible ETL anti-patterns. When I fix those anti-patterns everything just magically runs better. I have yet to touch actual ETL code.
Unfortunately, too many job postings ask candidates to have specific ETL tooling experience such as SSIS or DataStage. This is unfortunate. Too many candidates have great tooling experience but have very little grounding in ETL best practices, regardless of chosen tool. I've been called in a lot lately to help fix various ETL processes. Each one is using a different ETL tool and each one is exhibiting the same terrible ETL anti-patterns. When I fix those anti-patterns everything just magically runs better. I have yet to touch actual ETL code.
 To quickly summarize the most egregious issue...developers are doing too much work in the ETL tool and not enough work in their RDBMS. The RDBMS will almost always do things faster than the ETL tool can. There are few exceptions to this rule (string manipulation and regexp is better in most ETL tools than in SQL for instance).
To quickly summarize the most egregious issue...developers are doing too much work in the ETL tool and not enough work in their RDBMS. The RDBMS will almost always do things faster than the ETL tool can. There are few exceptions to this rule (string manipulation and regexp is better in most ETL tools than in SQL for instance).
I've written tons of blog posts (here's a link to an entire series of ETL Best Practices) about how to do performant ETL with good patterns. However, I find myself constantly searching my blog to find a succinct list of things to check whenever I'm brought into another ETL engagement. Here's the biggies:
- [[ETL Best Practices]]. I'm not going to list all of them. That's a long blog post. You should go reference that.
- Do more in SQL and less in the ETL tool. Examples:
- SSIS is not available in SQL Express
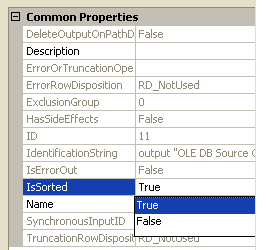 Sorts are better handled in the RDBMS. Use an ORDER BY clause on your SQL statement instead of relying on your ETL tool to sort. If using SSIS, mark your OLEDB source metadata on the data source as sorted.
Sorts are better handled in the RDBMS. Use an ORDER BY clause on your SQL statement instead of relying on your ETL tool to sort. If using SSIS, mark your OLEDB source metadata on the data source as sorted. - Any set-based, relational operation will be faster in SQL than in your ETL tool. Your RDBMS will likely automatically determine the best parallelism and memory management to use. On the contrary, you'll never get this right in your ETL tool.
- Big packages are not good. If your SSIS package is swapping to disk then you are not running efficiently. There is a SSIS performance counter called "Buffers Spooled". It should always stay at 0. Always. Otherwise you are using your swap file.
- If you run Integration Services on your SQL Server then use the "SQL Server Destination" vs the "OLEDB destination". Performance is markedly better.
- Understand and optimize your data structures. Examples:
- Understand locking, [[Lock Escalation]], and transaction isolation semantics for your given RDBMS. If using SSIS then understand the difference between [[BATCHSIZE vs ROWS_PER_BATCH]] and ensure they are optimized for your destination RDBMS.
- [[Partitioned Tables]]. Understand them and try to use them if your destination is SQL Server. The SWITCH statement is your friend, maybe your best friend.
- Make sure you are always doing [[Minimally Logged Operations]] whenever possible. And always verify with testing and performance monitoring. Every RDBMS has different rules for what equates to a minimally logged operation.
- Determine whether it is faster to disable/drop your indexes before your data loads. There is lots of conflicting guidance and there is no substitute for testing. I've found that every engagement a different setting is needed. Here is some additional guidance you may not find elsewhere:
- A commit size of 0 is fastest on heaps
- if you can't use 0 because you have concurrency concerns then use the highest value you can to reduce the overhead of multiple batches and transaction control.
- A commit size of 0 on a clustered index is a bad idea because all incoming rows must be sorted. This will likely cause spooling to tempdb which should be avoided.
- There are network-related settings that are invaluable for performance:
- jumbo frames will increase your packet payload from 1500 bytes/frame to 9000 bytes/frame.
- Change sqlConnection.PacketSize. The default is 4096 bytes. That's small for moving around large amounts of data. 32767 would be better.
- use network affinity at the OS level.
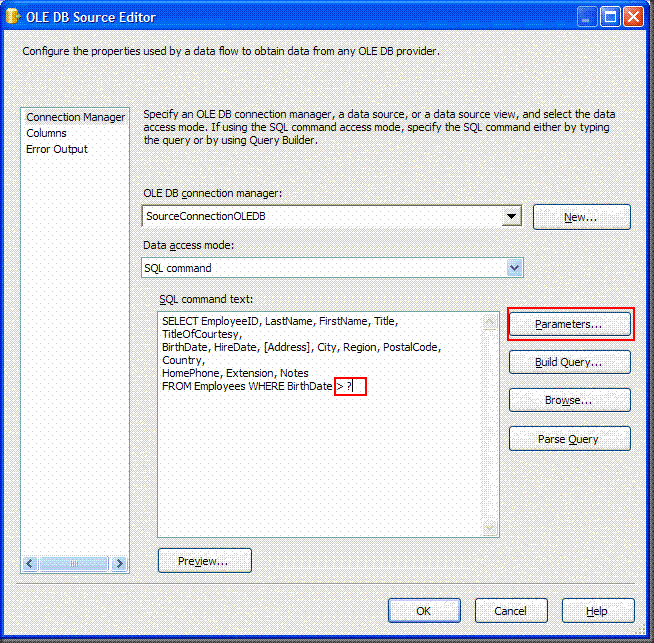 When using the OLEDB source, always set the Data Access Mode to "SQL Command". Never "table or view". Performance is almost always better. The reason is that sp_prepare is called under the covers using the latter and therefore has a better shot at getting a good execution plan. The former does the equivalent of a SET ROWCOUNT 1 to get its column metadata. That can lead to bad execution plans.
When using the OLEDB source, always set the Data Access Mode to "SQL Command". Never "table or view". Performance is almost always better. The reason is that sp_prepare is called under the covers using the latter and therefore has a better shot at getting a good execution plan. The former does the equivalent of a SET ROWCOUNT 1 to get its column metadata. That can lead to bad execution plans. - You should seriously consider restructuring your ETL processes so they work like a queue. I'll cover this in the next post, [[Structuring Your ETL like a Queue]].
Dave Wentzel CONTENT
sql server data architecture etl