
Handling Conflicts with Eventual Consistency and Distributed Systems
In distributed data architectures like some NoSQL solutions, a mechanism is needed to detect and resolve conflicting updates on different nodes. There are many different ways to do this. You don't need to understand the nitty gritty details of how this is done, but understanding the basic concepts is fundamental to understanding the strengths and limitations of your distributed data system. In this post I'll cover some of the methods.
Distributed Hash Tables
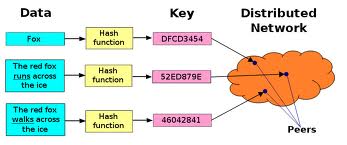 BitTorrent's distributed tracker uses this technology. In fact, some key-value systems like Cassandra and memcached (I'll cover both in a later post) are just giant DHTs. Essentially a data element is passed to a common hashing function to generate a key, which is then passed around to other nodes.
BitTorrent's distributed tracker uses this technology. In fact, some key-value systems like Cassandra and memcached (I'll cover both in a later post) are just giant DHTs. Essentially a data element is passed to a common hashing function to generate a key, which is then passed around to other nodes. Quorom Protocol
Very simply, technologies that use QP must "commit" on n number of nodes for the transaction to be considered successful. The "commit" can be handled in one of two ways:
- Like a traditional two-phase commit (2PC). In this case the write commit is delayed until a quorum of n acknowledge the change. Obviously this can introduce a high amount of transaction latency.
- The quorum is obtained on the read side. When the data is read the quorum is obtained then. Again, latency is introduced in this model.
Gossip Protocol
This method allows nodes to become aware of other node crashes or new nodes joining the distributed system. Changes to data are propogated to a set of known neighbors, who in turn propogate to a different set of neighbors. After a certain period of time the data view becomes consistent. The problem is that the more nodes the system contains, the longer it will take for updates to propogate, which in turn means the "eventual consistency" takes longer and therefore the possibility of conflicts occurring increases.
Vector Clocks
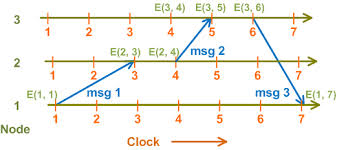
A vector clock is probably the simplest way to handle conflict resolution in a distributed system. A vector clock is a token that distributed systems pass around to keep the order of conflicting updates intact. You could just timestamp the updates and let the last update win...if your requirements are that simple. But if the servers are geographically disparate it may be impossible to keep the clocks synchronous. Even using something like NTP (Network Time Protocol) on a LAN may not keep the clocks synchronized enough. Vector clocks tag the data event so that conflicts can be handled logically by the application developer. This is basically how Git works under-the-covers.
There are many ways to implement vector clocks but the simplest way is for the client to stamp its data event with a "tag" that contains what the client knows about all of the other clients in the distributed system at that point in time. A typical tag may look like this:
client1:50;client2:100;client3:78;client4:90
Assuming this was client1, the above tag indicates client1 knows that client2 is on its "Revision 100", client3 is on its "Revision 78", client4 is on its "Revision 90" and it is on "Revision 50". "Revision" in this sense is a monotonically increasing identifier specific to that node. You could use a GUID, but that is rarely done.
Problems with Vector Clocks
A vector clock tag grows very large as more clients participate in the system, and as the system generates more messages. Some vector clock-based systems like Riak have a pruning algorithm to keep the vector clock tags more compact. Vector clocks are also used by Amazon's Dynamo architecture.
Dave Wentzel CONTENT
sql server data architecture service broker nosql