If you use TSQL UDF's (and you really shouldn't be in many cases), make sure you use WITH SCHEMABINDING. The performance improvement is STAGGERING. Let's look at an example. Here we have a typical scalar UDF, it takes a series of inputs and nicely formats a telephone number. Very simple.

For the demo I have 2 versions of this function...one WITH SCHEMABINDING and one without. Here is the demo file. And here are the functions I will use for the demo.
After looking at the UDF it is clear that it does NOT actually access any data in our database. We build a new db from scratch and have not created a table so that should be obvious.
Whenever you create a UDF two metadata properties are flagged...whether or not the function accesses system data and whether it access user data. Here's where it gets interesting. If we don't specify SCHEMABINDING then SQL Server marks our function as accessing system and user data. It is basically the DEFAULT.
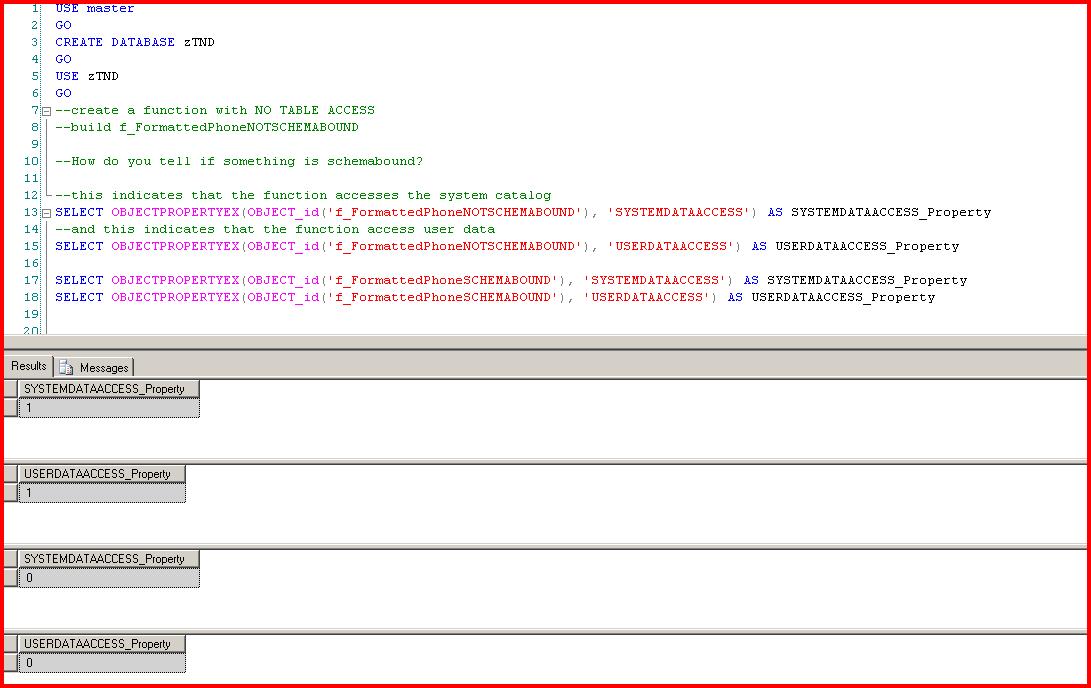
Why does SQL Server do this? There is, I guess, no way for SQL Server to know that anything referenced by the function has not changed since the function was created. SQL Server would need to do this check on EVERY invocation causing a big performance hit. So the safe thing to do is to mark the function as accessing system and user data. You can think of this as marking the UDF as UNSAFE. Again, I'm assuming this is the rationale the folks at Microsoft used.
Whenever the values are set to 1 then any query plan referencing the UDF will have an extra "Eager Spool" operator (I've written about these lots of times) inserted around the UDF if it is accessed as part of an INSERT, UPDATE, or DELETE statement. Why? "Halloween Protection".
What is Halloween Protection?
I've written about [[More on the Halloween Problem|Halloween Protection]] before. In its simplest form, the Halloween Problem occurs when we read and write keys of a common index. Think of an Employee table with an index on Salary. The requirement is to give everyone a 20% raise with a salary > 20000.
UPDATE Employee SET Salary = Salary * 1.20 WHERE Salary > 20000
The index on Salary will be used to find the rows to be updated. But the process of updating a row's Salary will cause the index key to migrate to a new location which could cause it to be re-read and re-updated, even causing an infinite loop situation. Halloween Protection is the process (actually defined in the ANSI SQL standard) where a read-consistent view of the updateable keys is squirreled away in temporary storage and then used as the replacement for the WHERE clause condition.
The process of building a read-consistent view of the data is implemented in SQL Server as an "Eager Spool". These are a performance nightmare and should be eliminated whenever possible.
How is this relevant to unbound scalar UDFs?
If a UDF is not schemabound then SQL Server must assume that the UDF may actually change data referenced in the outer query's FROM clause, meaning that we see an Eager Spool in our query plan.
Continuing the Example
Let's build a PhoneNo table with columns that will map to our scalar UDF. Let's also throw some junk data into the table.
Just running a simple SELECT will not give us an Eager Spool. Nothing is changing so we don't need to worry about it. A standard shared lock during the read (assuming you are running in read committed mode) is good enough.
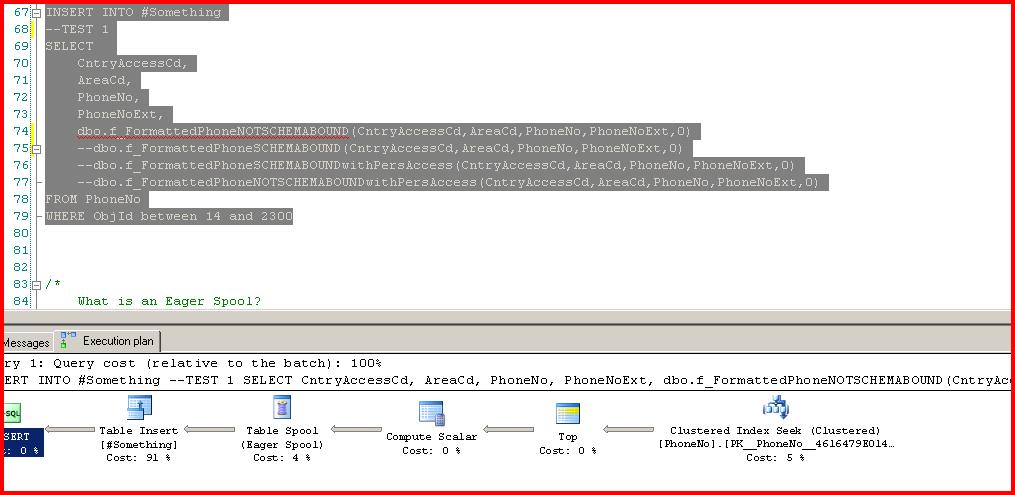
But let's assume we need to INSERT the output of our scalar UDF call into a temp table, possibly for further processing in a stored procedure. The example code below makes 4 different calls to our 4 different scalar functions. In this screenshot we call the unbound function. Note the Eager Spool.
This makes sense given that the query engine must handle Halloween Protection. It only costs 4% of the total query plan, but this is a simple example (and please hold that "only 4%" thought for a moment). Now let's run the schemabound function:
Cool. No Eager Spool is needed this time, which makes sense.
OK, but the Eager Spool was only 4% of the query plan. No big deal.
Wrong!
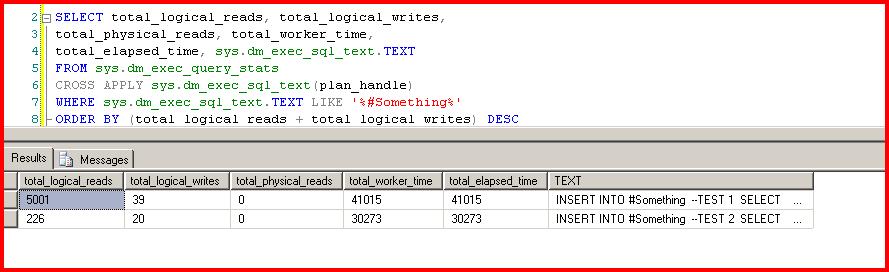
If we run the two tests again, but run DBCC FREEPROCCACHE first, we can see what our performance numbers look like:
--TEST 1 is the plan with the Eager Spool. That is incredibly poor performance due to simply forgetting to schemabind your function.
Summary
In the example files (
here and
here) I also have calls to scalar UDFs that access user data. SCHEMABINDING these UDFs doesn't yield much of a performance improvement. In fact, in some cases the performance is EXACTLY the same, almost indicating that SCHEMABINDING makes no difference on scalar UDFs that access persisted table data. Other times performance is slightly better. On very rare occassions I do see staggering improvements, but it is rare. I'm not sure what the pattern is...I'm still researching.
Ultimately, the correct solution is to *not* use scalar UDFs if you absolutely do not need to. Performance is ALWAYS better using an alternative such as inlining the function logic or using a stored procedure. YMMV.
My next post will be a deeper dive into [[They Should Call Them Evil Spools|Eager Spools]].