In this NoSQL post I want to share my predictions for the future of NoSQL. But to understand my predictions you must understand the history of data management. This will be REAL brief. It kinda all starts with Codasyl. Codasyl (Conference on Data Systems Languages) was a consortium started around 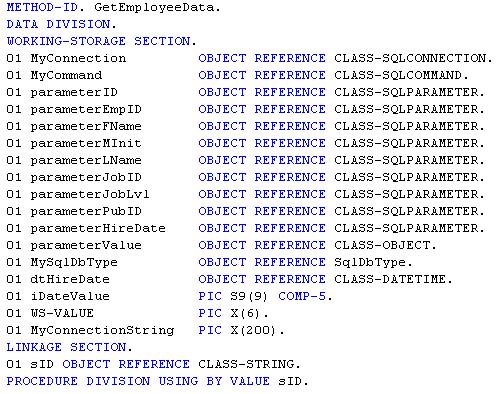 1959 to develop a standard data programming language that could run anywhere and was easy to learn. The first attempt gave us COBOL (COmmon Business Oriented Language). Within 10 years COBOL evolved to include a DML and DDL language that, though not relational (more like a [[Data Models and Data Organization Methods|network model]]), worked well. At some point there was a realization that a specific higher-level declarative "data" language was needed. This was the early 1970s and IBM was looking for a data language for their relational System R and implemented and championed SQL. That was a VERY concise history lesson. Codasyl is mostly dead today due to the advent of relational models and "SQL" but they do have some niches. Healthcare (one of my areas of expertise) is one. In my mind this means that either a)businesses are too cheap to rewrite these apps into something more modern/relational or b)they just work and relational/RDBMSs maybe aren't the best solution.
1959 to develop a standard data programming language that could run anywhere and was easy to learn. The first attempt gave us COBOL (COmmon Business Oriented Language). Within 10 years COBOL evolved to include a DML and DDL language that, though not relational (more like a [[Data Models and Data Organization Methods|network model]]), worked well. At some point there was a realization that a specific higher-level declarative "data" language was needed. This was the early 1970s and IBM was looking for a data language for their relational System R and implemented and championed SQL. That was a VERY concise history lesson. Codasyl is mostly dead today due to the advent of relational models and "SQL" but they do have some niches. Healthcare (one of my areas of expertise) is one. In my mind this means that either a)businesses are too cheap to rewrite these apps into something more modern/relational or b)they just work and relational/RDBMSs maybe aren't the best solution.
But why did relational managers take off while network data managers died out? The biggest reason is that most business problems are better modeled relationally. Next, relational vendors had all adopted SQL. Network/hierarchy models had disparate, fragmented languages. Suddenly things were cross-vendor-capable in the relational world, and even when vendor SQLs weren't perfectly compatible (even today PL/SQL is definitely different from TSQL) at least the learning curve wasn't very steep (for instance, JOIN syntax is a little different among vendors, but semantically the same). That cannot be said for hierarchical and network managers. They each had their own language. Some looked Algol-ish, others looked like Fortran, etc. No standards = less adoption.
The lesson is low-level user interfaces for data manipulation is not a good idea if you want market adoption.
 SQL, for all its faults, is easy to learn. Not so for network and hierarchy managers. MUMPS (a hierarchical system that is older than me and still used in healthcare today) has a horrendous language (called M) to learn.
SQL, for all its faults, is easy to learn. Not so for network and hierarchy managers. MUMPS (a hierarchical system that is older than me and still used in healthcare today) has a horrendous language (called M) to learn.

If you've never written a "query" without a declarative language, like SQL, on a old-time database manager...well, you're missing out on some real fun. Imagine writing code to open a "file" on a tape and implementing a "nested loops" construct to join it to another data file. You might have heard of this before...it's called ISAM (or, later, VSAM, which was a little better) and it is up to you to understand the physical retrieval of the data vs just worrying about declare what you want (like SQL). Worrying about physical retrieval of data is fraught with danger. Lots of bugs if you are a novice and don't understand hashing and indexing.
These physical data retrieval issues were soon identified and rectified with ISAM after it was first released. It didn't take long before IBM realized that a "query optimizer" embedded in the product could determine for the business user how best to tackle a query. And then ISAM got popular.
To repeat...the lesson is low-level user interfaces for data manipulation is not a good idea if you want market penetration. Higher level languages brought relational databases to the masses. You didn't need to be a programmer to use them. The same thing will happen with NoSQL. That's my prediction. When the process of writing MapReduce jobs is no more complicated than writing a HiveQL statement, then NoSQL products will really take off.
We seem to be repeating history a bit and re-learning the lessons of the past. Writing MapReduce seems to me to be equivalent to writing ISAM code. It's tedious, can perform poorly if your knowledge of how data persistence works isn't good, and is prone to error. This isn't the first time our industry has retrogressed in data management. 15 years ago XML was being touted as the app that would finally kill the relational database. Obviously "tag bloat" is probably the biggest reason that never occurred, but another reason is simply the effort and learning curve needed to query XML. It's getting better, but it's still not easy enough for dumb guys like me. And look at how many methods exist to query XML...XQuery, XQL, XPath, XSLT. That's not user-friendly...and user-friendly is how you win business.
So what NoSQL needs, IMHO, is a standards-based approach to querying that the average business person can use. Something like HiveQL. And a lot of the vendors understand this too and are developing really good tools that are close enough to SQL that the average business person will enjoy learning them.
I did.
But the problem is there is no standard, so each vendor's query language can be very different. But the common denominator is they all try to model themselves on SQL.
I've already written about [[Querying NoSQL with Hive and Pig|HiveQL]] as an example of a declarative language. Another example is CQL, which is Cassandra's query language. I did not get a chance to work with CQL closely, but the DML syntax, at least, is almost exactly like ANSI SQL. There are of course extensions to the language to handle those items unique to Cassandra and NoSQL that you won't see in a relational language, such as BATCH (makes multiple DML statements work atomically), CREATE KEYSPACE (document definitions), and CONSISTENCY (concurrency isolation level control). There's the rub...those "statements" that are specific to non-relational products need to be standardized. KEYSPACE in one product is DOCUMENT in another.
As of late 2011 Couchbase even has a "SQL" dialect originally called UnQL (pronounced "uncle"). They have since renamed it to N1QL (pronounced "nickel"). It is still in beta but shows promise. Again, we dismissed Couchbase due to requirements, otherwise I think it would've been interesting to learn nickel (and hopefully I wouldn't have to cry "uncle" trying to get it to work). N1QL also provides a series of DDL commands, just like ANSI SQL. Couchbase has an excellent tutorial with sample documents and how to query them effectively.
There's a trend here. More complete higher level languages will win more converts to NoSQL. In fact, if we could somehow get a proposed NoSQL language standard, like Codasyl championed, we may see mass adoption. Write MapReduce or curl or java just won't cut it.
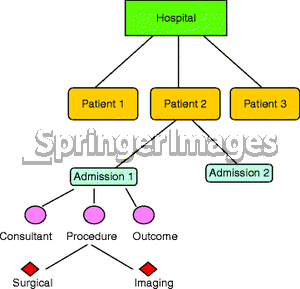
Lastly, unlike most of my RDBMS collegues, I do believe there is a need for NoSQL products on both a logical and physical level. On the relational theory side, there are some things that just can't be modeled well relationally. Graph databases fill one such void. Think about the web of connections in your LinkedIn profile. It's difficult to model these relationships relationally. This is probably because most modelers (myself included) feel more at home with physical modeling than logical modeling. The physical model for something like LinkedIn, if done in a purely relational database manager would be horrible. In a graph db things are much easier. Modeling hierarchies and transitive closure-type relationships is conceptually difficult for most people in a relational model. Why not just stick with a product that is actually hierarchical.
Regarding implementation/physical rationales for NoSQL, as we've seen in these posts, there are cases where the physical persistence implementation by the major RDBMS vendors is not always optimal. There are excellent use cases for columnstores for instance. Or totally in-memory RDBMSs (SAP HANA). Or RDBMSs that natively support sharding while hiding the implementation details (Oracle grid stuff). If there weren't, then we wouldn't see these features being bolted-on to the RDBMS vendors' products with every new release.
I think the future of NoSQL is bright and I'm looking forward to working with these products and better understanding the technologies and theories behind them.
