
Just How Expensive is a Bookmark Lookup in a Query Plan
Yesterday I mentioned a conversation with a co-worker where he asked [[Just How Expensive is a Sort Operator in a Query Plan]]? I showed using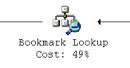 mathematics and theory that they are very costly. As a followup my co-worker asked why, after eliminating the Sort Operators, did I focus on the Bookmark Lookups? Why exactly are Bookmark Lookups so bad for performance? Isn't it simply using a second index to get the data that is required? Isn't this better than potentially scanning a clustered index directly?
mathematics and theory that they are very costly. As a followup my co-worker asked why, after eliminating the Sort Operators, did I focus on the Bookmark Lookups? Why exactly are Bookmark Lookups so bad for performance? Isn't it simply using a second index to get the data that is required? Isn't this better than potentially scanning a clustered index directly?
SQL server he is smart enough to consider using more than one index to satisfy a given query. There are multiple ways SQL server can do this. One way is to join two non-clustered indexes together to "cover" all of the columns required by the query. This is known as "index intersection."
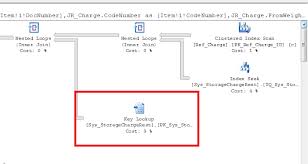
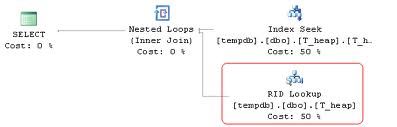
If it is not possible to cover all the columns required by the query using non-clustered indexes, then the optimizer may need to access the base table to obtainthe remaining columns. This is known as a bookmark lookup operation. In the table has a clustered index this is known as a Key Lookup. If the base table is a heap, this is known as a RID Lookup.
Given the choice of index intersection or bookmark lookup, the former is always better. Why?
(An example of index intersecton)
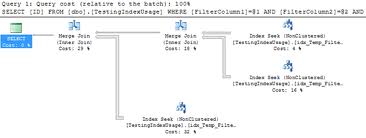
Just like a standard SQL JOIN an "index intersection" is simply joining two data structures by their key. The data retrieval is handled as sequential reads. This is very efficient, even over very large result sets.
A bookmark/key/RID lookup also joins on the key, but in this case the leading column of the non-clustered index is not the leading column of the clustered index. The non-clustered index contains the clustered index's key, but it isn't the leading column. The data access, therefore, will not be sequential, instead requiring random I/O, which is a very expensive operation. its usage can be effective only for a relatively small number of records. This is why it is sometimes more efficient for SQL Server to NOT use a non-clustered index to satisfy a given query if it is not a covered index. Instead, SQL Server may choose a clustered index scan instead.
[[Key Lookups]]
Dave Wentzel CONTENT
sql server performance